
物理页框维护
上一篇博客我们介绍了内核的内存管理,内核被加载到了物理内存的低位(1M)开始的位置,但是内核的线性地址被平移到了 [3G, 4G),通过内核页表维护 这种映射关系。所有进程的 [3G, 4G) 页表项都从内核页表中拷贝过来,从而实现将内核映射到进程线性地址空间的高 1G。
今天我们介绍内核是如何管理物理页框的,因为不管是内核还是进程,在解析线性地址时都可能需要分配对应的物理页框。内核维护物理页框 需要元数据,这些元数据空间需要实际的物理内存占用,所以为了避免鸡生蛋蛋生鸡的循环,物理页框的元数据直接在内核的数据段,不需要 通过内核分配器分配内存。
对于物理页框,我们需要描述物理页框的特权级、用途、引用计数、页框链接头等信息,所以实际每个物理页框需要 32bit 的页框描述符,由于 页框大小一般选择 4K,所以为了维护物理页框的状态,需要大概 1% 的内存空间。所有页框的描述符被组织到一个数组中,通过页框的索引号就 能直接在该数组中找到对应的页框描述符。
物理内存划分
上面我们在维护物理页框描述符时一直有个假设,就是这个内存是个连续的物理地址空间,感觉 CPU 在访问所有内存物理地址都是一样的,我们
称这种架构为 Uniform Memory Access(UMA)。
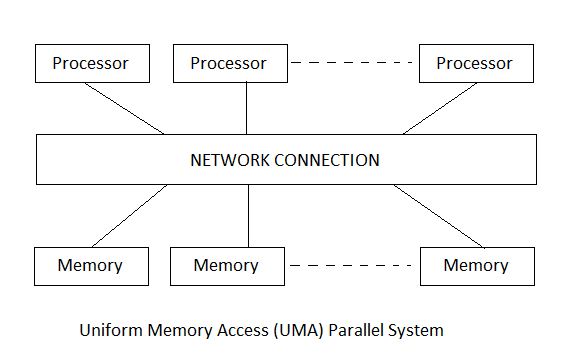
更多的,我们可能存在多个物理内存节点,不同的 CPU 访问不同的物理内存节点延迟是不同的,CPU 访问
特定内存节点速度会更快,我们称这种架构为 Non Uniform Memory Access(NUMA)。
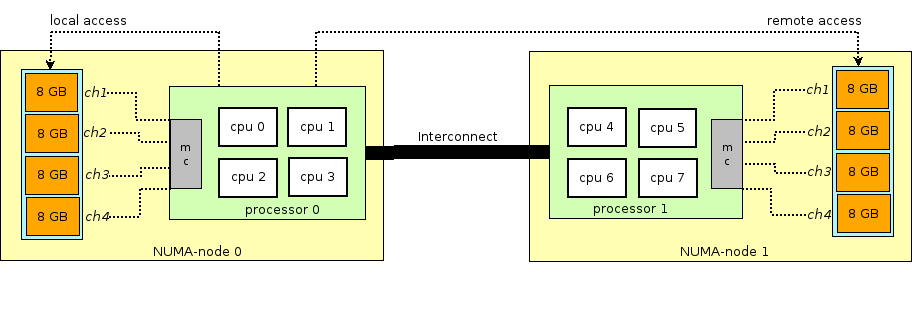
对于每个物理内存节点,虽然理论上对于任何物理页框请求需求,我们可以分配任意物理页框,但是实际上内核对于不同物理地址范围的使用做了一些约定,
比如 [0M, 16M) 用于分配给 DMA(Direct Memory Access) 做磁盘和内存之间的数据存取。对于 [16M, 896M),可以正常使用。对于大于 896M 物理地址空间,
就有些特殊,我们称之为 HighMemory。之所以特殊是因为我们知道内核被映射到线性地址的 [3G, 4G) 空间,也就是说内核在同一个时刻最多使用 1G 的物理
内存。其中 [0, 896M) 物理内存是固定 1:1 线性映射,也就是线性地址 = 物理地址 + 0xC0000000,所以物理内存中大于 896MB 的部分被特殊对待了。
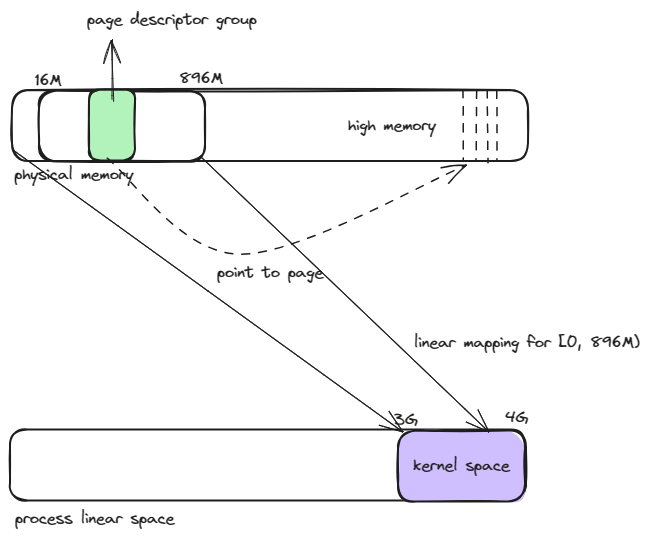
source
[0, 896M) 物理内存被线性映射之后,内核只剩下 [3G+896M, 4G) 这部分 128MB 的线性地址,这部分末端的线性地址空间不再是 1:1 映射到低地址,否则内核 就无法利用到大于 1G 的物理内存空间。
为了实现内核可以访问物理地址 HighMemory, 内核需要充分利用 [3G+896M, 4G) 这个线性地址范围对应的页表项,将 HighMemory 中物理页框索引项填充到对应的 页表项中。可利用的页表项有 128M/4K = 32K,共 32 个页表。
内核提供了 3 种方式利用这个 32K 个页表项。
1.非连续内存映射
[16M, 896M) 对于线性空间和物理空间都是连续的,所以我们可以很方便得申请连续地址空间,比如申请 12K 的线性地址空间,底层的物理地址空间也是连续的,对于 一些连续数据计算是很有帮助的。同时,对于 DMA 等操作,需要能申请到连续的物理页存储数据。 但是对于另外一些场景,对于连续跨页内存操作的性能要求不是很高,此时我们可以接受连续的线性地址空间背后是离散的物理内存页。这就是非连续内存映射,其实和 进程申请线性地址,触发缺页中断后分配可用物理页差不多。
2.永久内存映射
永久内存映射的基本原理是,专门在这 128M 地址空间中划分出一块线性空间的子集,我们称为永久映射内存空间,它对应一系列连续的页表项。当我们需要将大于 896M 的物理页映射到内核永久映射内存空间时,首先申请一个可用的物理页,然后线性搜索永久映射内存空间的一个可用的页表项。如果没有可用页表项,就阻塞申请内存的执行单元, 等待有其他线程释放页表项之后再唤醒等待的执行单元。由于可能阻塞执行单元,所以不适合类似中断处理程序等不能被阻塞的内核路径。
内核中有个实现的细节,page_address(struct page*) 会接受一个页框描述符的线性地址,返回页框对应的线形地址。我们知道页框描述符数组肯定存在物理内存的低896M, 所以页框描述符的线性地址也是 1:1 线性映射的。但是页框的线性地址就有 2 种可能,一种是页框属于小于 896M 的物理内存空间,此时根据页框描述符计算出页框的索引, 从而可以得到页框的物理地址,再将物理地址加上 0xC0000000 就可以得到页框的线性地址。一种是页框属于物理内存空间的 HighMemory 部分,这部分地址映射没有规律,需要 线性搜索整个永久映射内存空间。为了加速这个过程,内核维护了页框描述符线性地址到页框线性地址的 Hash Table。
3.临时内存映射
不同于永久内存映射,临时内存映射专门在 4G 线性地址空间的末端预留出了不同用途的页表项作为物理页框到线性页框的映射。也就是说,任意 HighMemory 对应的物理页框是 使用固定线性地址的页表项进行映射的,不同于永久内存映射是搜索一个可用页表项。临时内存映射要求调用者不能并发对同一个用途的页表项进行映射,从而保证内存映射是安全的, 所以这个内存映射的方式不会阻塞调用的执行单元,毕竟安全问题转移给了调用者。
Buddy System
说到这里,我们就大概了解了整个内核 1G 的物理内存空间和线性内存空间,下面我们讨论下物理页框是如何分配的。从管理的角度看,内核首先维护了内存节点相关的数据结构,在
这些结构体中我们可以维护关于 CPU 亲和力等相关信息(NUMA),然后根据内核对页框的用途不同,在内存节点结构体内部维护了不同的内存管理区数据结构(DMA//Normal/HighMemory)。
每个内存管理区则维护了物理页框相关的数据结构维护页框的使用状态。所以在页框管理结构上形成了 Node -> Memory Zone -> Page List 的层次结构。
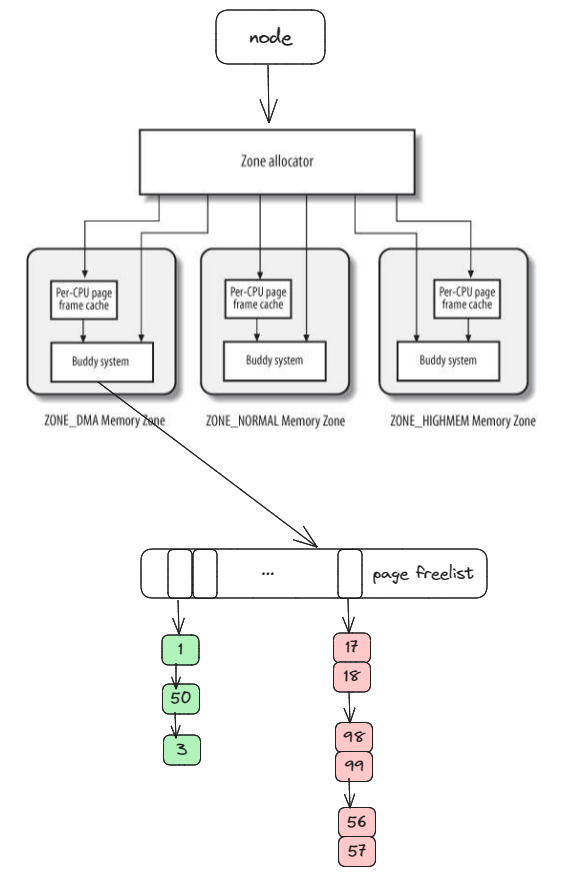
source
由于对于物理页框的分配需求是多种多样的,所以基于内部碎片和外部碎片问题的考虑,页框的维护使用了比较经典的算法,也就是按照连续页框的大小划分不同等级(order)的链表。
比如在每个内存管理区内维护大小分别为 1,2,4,8,16,32,64,128,256,512,1024 个连续页框的链表,每个链表中的元素表示连续页框个数都是 2^order,并用第一个物理页
的地址作为这个内存块的代表。
举个例子:
由于每个物理内存页都是 4K 对齐的,我们假设两个地址连续的物理内存页地址分别为 0x00012000 和 0x00013000,将这两个物理页看成一个整体,用0x00012000 作为整个内存块的
代码,并设置这两个物理内存页对应的页描述符中 order = 2。
让我们考虑下关于物理页框的分配问题,假如现在我们需要 order = 5 的连续内存块,由于 order = 8 以下的页框链表无法满足需求,如果 order = 8 的链表刚好有空闲内存块,则 取出一个 8 个连续页框的内存块,直接分配给调用者。如果 order = 8 的链表没有空闲内存块,再线性往上找。
当调用者要释放一个内存块时,我们从内存块的首地址中获得第一个物理页的索引,从而找到对应的页描述符,从而知道这个内存块中每个物理页的 order。此时我们可以简单得把它插入
到对应 order 的链表中,但是为了避免外部碎片,也就是大量离散小物理页无法满足连续大内存块的分配需求,我们需要做一定次数的合并尝试,将要释放的内存块和相连的相同 order 的
内存块合并成更大 order 的内存块,然后插入到更大 order 对应的链表中。
举个例子:
现在要释放地址为 0x02003000 的内存块,通过查找对应的页描述符发现它的 order 是 2,也就是这个物理内存块由两个连续的物理内存页组成。如果这个内存块相邻的内存块也刚好是
order = 2 的空闲内存块,就可以合并。现在我们需要查看 0x02001000 或者 0x02005000 物理页对应的 order 是否为 2 ,是否是空闲的,如果都不是空闲的就结束合并过程。如果是空
闲的就再用类似的过程合并新生成的 order = 4 的空闲内存块。
在查找相邻相同内存块过程中,一个更快的方式是:
(address » page_shift) ^= (2^order),通过将对应 order 位置 bit 取反我们能快速得到相连相同 order 的内存块地址,再检查这个内存块地址对应的页框 order 和空闲标志是否符合
预期即可。
关于空闲链表的维护,在前面我们说了为了维护页框状态,包括访问权限,读写权限等之类的信息,每个页框都会对应一个页描述符。所有的页描述符都存储在连续的数组中,用数组序号索引对应的页描述符。 页描述符数组的内存不是动态分配的,因为页框维护算法是内核内存分配算法的基础,它所有的元数据都是在内核初始化时直接在某个物理地址直接根据需求大小初始化的,相当于某种程度的 bootstrap。 更有趣的说法是,我们手动构造除了一个鸡。构造这只鸡需要的工作量不大,一些 node 结构,zone allocator 结构和 buddy system 结构。
内存管理区和 Buddy System
Buddy System 具体负责页框级别的内存分配,本质上就是一个 order 的链表头数组,通过算法维护这个数组状态即可。在 Buddy System 之上,内存管理区还有更多实际的问题需要考虑, 比如为了减少 CPU 之间的同步,内存管理区为每个 CPU 预留了单个页框的缓存,预先将一些单个页框维护到这个缓存中,满足一些快速的单页框分配需求。在实现上,这种每 CPU 页框的 高速缓存实际上页就是一些维护状态的数据结构和空闲单页框的指针数组。
另外一个关于内存管理区的需求是需要做一些物理页框的预留控制,防止在内存吃紧时内核关键路径没法申请到物理内存导致系统状态异常。
总结
- 内核在物理内存的组织上分成 Node,Zone,Page Frame 3级结构
- 内核在管理内存时,不同级别在负责不同的事情
- Zone 级别需要考虑每 CPU 相关的高速缓存和预留控制等
- Page Frame 级别就是 Buddy System 算法,需要考虑对不同大小内存块的需求和外碎片的问题