
Linux Kernel 是个超级复杂的状态机,而内核镜像本身只是包含内核数据和内核指令的文件,这种文件按照内核文件规范组织内核数据和指令 。
- 其中内核数据本身包含了维护内核状态的基础数据,动态申请的数据则通过内核数据中的地址引用来实现寻址访问。
- 内核指令则描述了不同场景下内核数据的变更流程
内核是什么
上一篇博客中我们简要介绍了在我们程序背后,Linux Kernel 做了什么样的抽象。在我尝试进一步描述 Linux Kernel 如何做资源抽象和管理之前, 需要先说清楚 Linux Kernel 是什么。
Linux Kernel 是用户程序和硬件的中间层
首先 Linux Kernel 肯定是用户程序和硬件的中间层,因为我们在写代码的时候几乎从来没有直接操作过硬件资源,比如让显示器显示我们正在输入的内容, 比如接受键盘输入,比如操作 CPU/内存,比如操作磁盘。
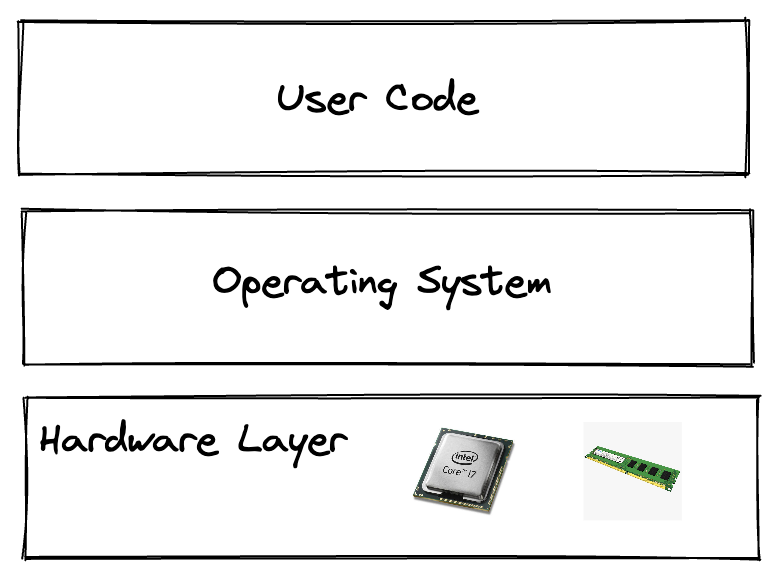
Linux Kernel 静态形式是文件
所以这个抽象概念上的中间层是什么意思呢
其实在最初的表现形式上是个文件,更专业的说法叫做内核镜像,所以我们在安装 linux 操作系统之前会拿到一个后缀是 image 或者 iso 的文件。这个内核
镜像中包含了硬件驱动,再加上一层封装,所以我们将内容输出到文件时,可能只是简单得调用一次 open 和 write,就能在磁盘中看到对应内容的文件。
Linux Kernel 的动态形式
那为什么最初的内核镜像和我们实际看到的运行环境差距这么大?
我们实际看到的是一个可交互可运行的环境,不是一个文件。还是需要回到一个非常原始的问题,我们在写完代码之后,机器运行代码,机器到底在做什么?
机器是什么?
机器是一堆电信号驱动的硬件。
- 比如 CPU 实际只是一个被时钟脉冲驱动着不断执行计算的硬件,不同类型的 CPU 在出厂时已经被设置好了根据引脚接收到的不同命令字执行不同的操作。不同 的命令字也就是我们说的机器字节码,汇编器就负责将汇编语言翻译成 CPU 可识别的机器字节码。
- 比如内存实际上是一个地址空间连续的存储硬件。机器在做的事情其实只是读取存储硬件上的数据,做一些计算,然后写回存储硬件上。最后我们看到的是存储 硬件上数据变化的一系列过程。
那这个过程和内核文件有什么关系
内核文件里包含了内核需要的数据和操作数据的指令,机器通电时,包含在硬件内部的逻辑会读取内核文件,将内核需要的数据和操作数据的指令都加载
到内存中。同时 CPU 通过读取内存中的指令不断更新内存中的内核数据,这里的内核数据具体一点就是内核中的各种文件描述符/内存描述符/运行队列的队列头或
者链表头结构。这些描述符数据的更新对于 CPU 来说毫无意义,对 CPU 而言它只是按照指令对应的机器命令字更新具体某个位置的某一些内存单元而已。
所以 Linux Kernel 是什么?
Linux Kernel 静态看是一个包含内核数据和指令的文件,动态看是一个内核数据根据指令不断变更的状态机,比如从 0 -> 3 -> 2 -> 1 -> 9。可以说不只是内核,
我们写的程序也是在做一样的事情。我们定义一些变量,然后对变量执行一系列的操作,然后再根据变量的新状态再做一系列操作。最后其实我们得到的是变量的状态机,
计算以能量的形式被消耗掉了。
 source
source
所以 Linux Kernel 是什么?
虽然从本质上看,Linux Kernel 的确是一个内核数据的状态机,但是几乎所有的东西都可以理解成状态机。那 Linux Kernel 到底是什么?比如实际上我可以在 Linux
上提交很多任务,每个任务在内核中都需要新建一系列的数据维护其状态,内核一开始作为一个静态的文件,不太可能包含一些动态新建的数据。
内核需要包含动态生成的数据吗?借用 C 的 struct 和类型举个例子:
struct State {
int flags (4 字节)
double sizes (8 字节)
int length (4 字节)
}
struct 可以理解成一整块内存块,纯粹的内存块是没有意义并难以识别的,比如大家都是人,需要名字才能有效得指定和交流。我们将这个内存块叫做 State,State 内存块的大小是 16 字节。这 16 字节中最开始的 4 字节我们叫做 flags,中间的 8 字节叫做 sizes,最后的 4 字节我们叫做 length。假如我们有一系列操作,比如:
flags = 1
sizes = sizes + 2
length = length * 8
假如所有内存的初始值都是 1,进过上述操作之后,内存块的数据变成:
|------------|--------------------|-----------|
| flags | sizes | length |
|------------|--------------------|-----------|
| 4 bytes | 8 bytes | 4bytes |
| 0x00000001 | 0x0000000000000003 | 0x00000008|
|------------|--------------------|-----------|
假如 State 就是内核镜像的内核数据,将内核文件装入内存,假设我们从地址 0 开始放置 State,则内存一开始的 16 字节其实就是 State,对前 16 字节的 一系列操作就是对内核数据的操作。假如内存大小是 100,地址从 0 ~ 99,则 0 ~15 其实就是内核数据,那内核要怎么利用 16~99 呢?内核要怎么支持动态 数据呢?在内核中增加保存其他内存地址的数据就行,比如:
struct State {
int flags (4 字节)
double sizes (8 字节)
int length (4 字节)
int next (4 字节)
}
我们在内核数据中引入了额外叫做 next 的 4 字节数据。内核文件装入内存时,前 20 字节就是 State。假如想要利用 20 ~99 的空间,比如动态申请一个 2 字 节的空间(35~36) ,我们把这另外的 2 字节叫做 width。为了能找到并更新 width,我们可以将 width 的第一个字节的地址保存在 State 的 next 字段中,
next = 35
*next = 3
CPU 执行完以上 2 个指令后,第 16~19 个字节的值变成 35。这样我们就知道了 width 的位置,然后将 width 所在的第 35 ~36 字节位置的值更新成 3。
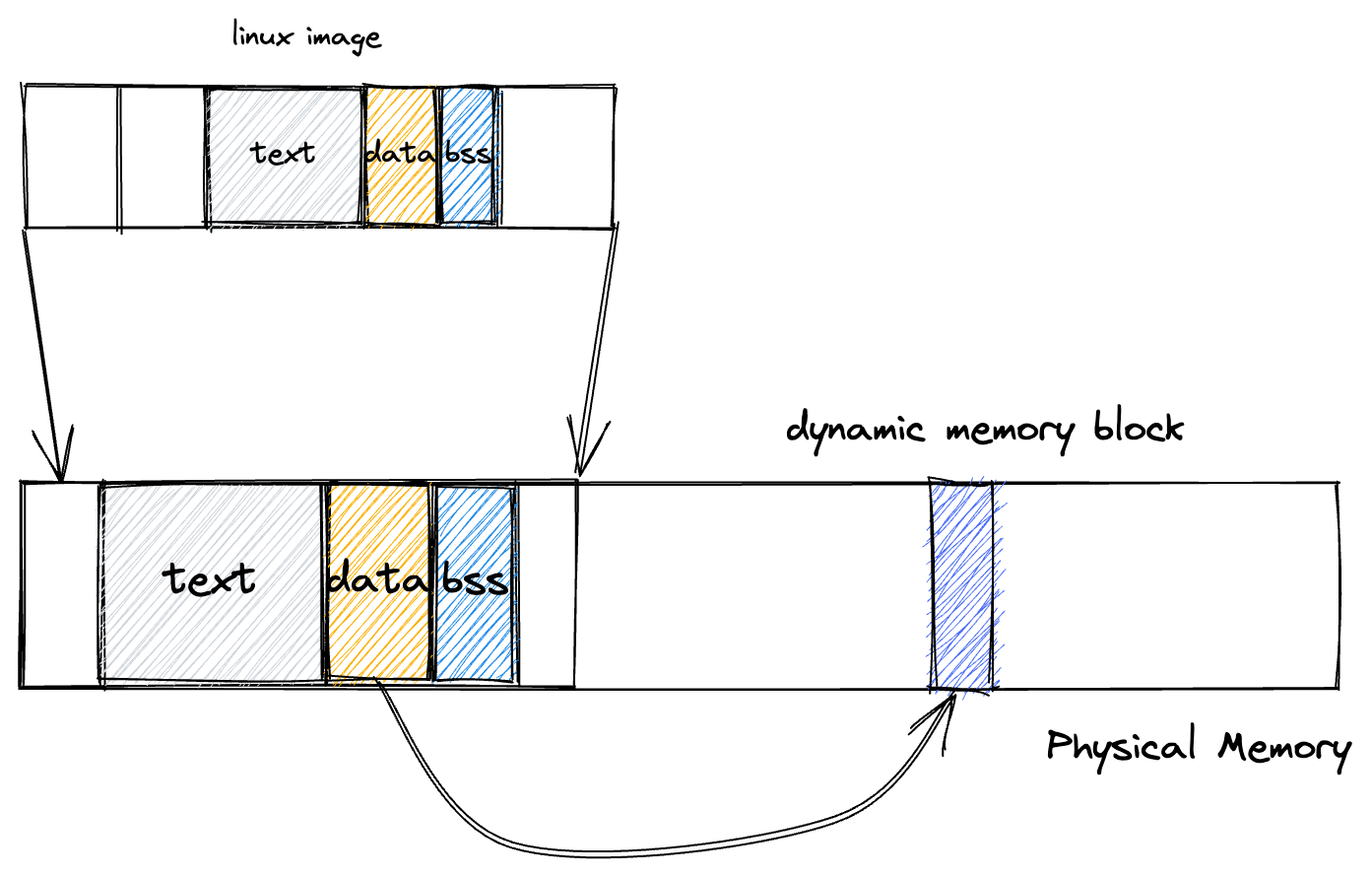
实际上内核也是类似这样子,内核文件只保留最基本的数据结构,比如固定长度是 8 字节的链表头,通过在 4 字节的指针变量中保存内存其他内容的地址就 可以找到内核维护的所有数据。
推荐阅读
想要了解更多相关内容,请直接阅读:
- 《Understanding The Linux Kernel》Daniel P.Bovet & Marco Cesati
- 《Modern Operating System》Andrew S.Tanenbaum & Herbert Bos
- 内核源码 https://www.kernel.org/