
NOTE: The content is derived from Algorithms, 4th Edition, mainly recording personal understanding of the algorithms. If you are interested or need the Java source code, you can directly read the online website graph. Enjoy it:)
Graphs
Graph structures are an important abstraction of the real world, representing relationships between entities and widely existing in various scenarios, such as:
- Maps: A very direct graph relationship where locations are vertices and roads are edges.
- Social networks: Each person has multiple friends, who in turn have friends, possibly forming cyclic acquaintance chains. Friend relationships are generally bidirectional, while follow relationships on platforms like Twitter are unidirectional.
- Website hyperlinks: As a classic distributed application, websites form a large-scale graph by maintaining hyperlinks to other websites.
- Product scheduling/trade relations/software design: These scenarios involve interactions between multiple modules, naturally forming a graph abstraction with vertices and edges.
Classic graphs can be divided into undirected graphs and directed graphs:
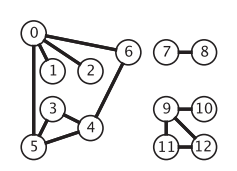
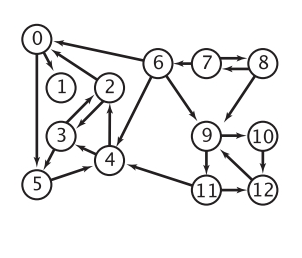
Properties of Graphs
Graphs consist of vertices and edges, with the following properties and related concepts:
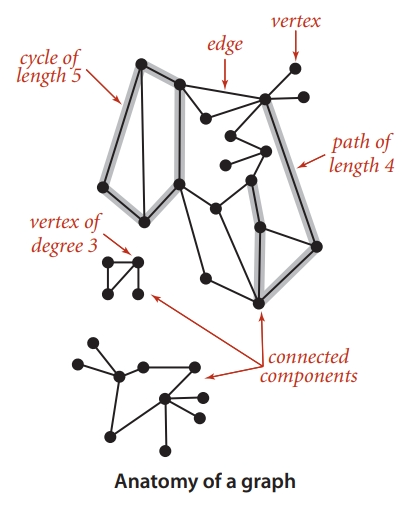
- Degree/in-degree/out-degree: The number of edges directly connected to a vertex is called the degree of the vertex. In directed graphs, the degree is further divided into in-degree and out-degree.
- Path/length of path: A series of vertices connected by edges is called a path, and the length of the path is the number of edges.
- Connected/connected component: A graph is connected if there is at least one path between every pair of vertices. A connected component is a subset of vertices that are all connected to each other. A graph may contain multiple connected components.
- Acyclic graph: A graph with no cycles is called an acyclic graph, which is a tree.
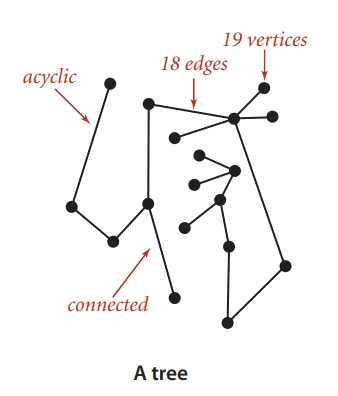
- Spanning tree: A tree that includes all vertices of a graph is called a spanning tree. A spanning tree has exactly V-1 edges, and adding any extra edge will form a cycle in the tree. For example, the shaded parts in the figure below are spanning trees of different connected components. Spanning trees play an important role in studying graph connectivity and minimum connectivity problems.
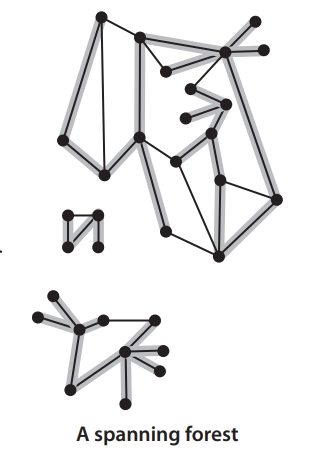
- Forest and spanning forest: A forest is a collection of trees, and a spanning forest is a collection of spanning trees.
Graph Representation and Operations
In the following representations, for clarity, we will separate graph behavior and graph implementation, and isolate graph operations such as search algorithms. Specifically:
- Graph behavior: Provides basic operations on graphs, such as the number of vertices, the number of edges, and the set of adjacent vertices of a vertex.
- Graph implementation: Specific methods for implementing graphs, such as using arrays or linked lists to store vertices and edges.
- Graph operations: Includes algorithms such as graph search, which can be independent and only interact with graph behavior, not with graph representation.
In describing graphs and graph algorithms, we use the object-oriented language C++. Object-oriented design methods effectively hide implementation details and clearly define the interaction boundaries of each component through public interfaces.
Graph Behavior
Whether it is a directed graph or an undirected graph, the graph behavior can be defined as follows:
/**
* @struct Graph
*/
class Graph
{
//
// behavior
//
public:
// ListIterator is the iterator for adjacency vertices list
typedef ListIterator<const Edge, const Edge*, const Edge&> const_iterator;
// constructor and destructor
UndirectedGraph(int V);
~UndirectedGraph();
// AddEdge adds a new edge to graph
// an edge includes <start vertex, end vertex, weight>
void AddEdge(int s, int t, double w = 0);
// Adj() returns a pair of const iterator [begin, end) for the adjective vertices list
std::pair<const_iterator, const_iterator> Adj(int v) const;
// Edges() returns a pair of const iterator [begin, end) for the whole edge list
std::pair<const_iterator, const_iterator> Edges();
// V() returns the number of vertices in graph
int V() const;
// E() returns the number of edges in graph
int E() const;
};
It is worth mentioning ListIterator. The design philosophy of iterators in C++ and Java is different.
Java’s Iterator
To reuse std::algorithm algorithms and encapsulate internal container implementation details, ListIterator and Iterator are defined. (This part needs to be rewritten later to avoid relying on std::algorithm, making the algorithm description more dependent on interface behavior!!!)
// std::algorithm style iterator interface
template <class Tp, class Ptr, class Ref>
class Iterator : public std::iterator<std::forward_iterator_tag, Tp,
std::ptrdiff_t, Ptr, Ref>
{
public:
typedef Iterator<Tp, Ptr, Ref> self_type;
virtual ~Iterator() {}
// [NOTE]: quite hard to override post-fix increment operator because it returns base object directly
// So we can use covariant return type technique in C++
//virtual self_type operator++(int) = 0;
virtual self_type &operator++() = 0;
virtual bool operator==(const self_type &) const = 0;
virtual bool operator!=(const self_type &) const = 0;
virtual Ptr operator->() const = 0;
virtual Ref operator*() const = 0;
};
template <class Tp, class Ptr=Tp*, class Ref=Tp&>
class ListIterator : public Iterator<Tp, Ptr, Ref>
{
//...
}
Graph Representation
Graph representation can vary based on different data scenarios and access patterns, which is what we often refer to as Data Model in storage.
-
For dense graphs, an adjacency matrix representation $graph[V][V]$ can be used. This method is characterized by compact data, good data locality, and high hardware cache hit rate. Picture from wiki.

-
For sparse graphs, adjacency lists can be used to save space.
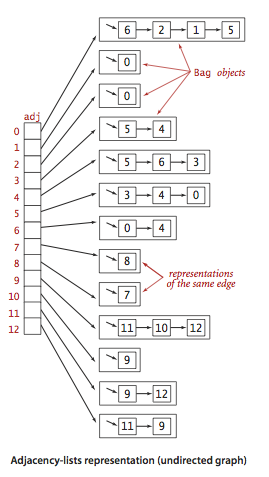
- For small graphs with fixed vertices and edges, arrays can be used to compactly store adjacent edges in each vertex, or edges can be compactly stored in an edge array classified by vertices. For example:
- Vertex array: [{0: [{0, 1}, {0, 2}]}, {1: [{1, 4}, {1, 3}]}, {2: [{2, 4}, {2, 1}]}, …]
- Edge array + length array:
edge array: [{0, 1}, {0, 2}, {1, 4}, {1, 3}, {2, 4}…]
length array: [0, 2, 4], indicating the starting position of edges in the edge array for different vertices
[TODO] graph
- Chain-forward array (chained array) representation of graphs combines the dynamic incrementality of linked lists with the data locality of arrays, often used in ACM problem-solving. For example:
const int MaxE=1000;
const int MaxV=100;
struct edge {
int to; // to vertex
int next; // points to net edge
} edges[MaxE]; // edge arrays
int head[MaxV]; // head for each vertex, points to adjacent edge list
The above defines an edge array compactly using arrays and uses the head array to store the head of the adjacent edge list for each vertex. [TODO] graph
- By leveraging imagination, there are various other representation methods. If the storage process requires organizing vertices and edges in the graph using an index, various index structures can be used based on access patterns, such as different tree structures—binary trees, red-black trees, AVL trees, and B/B+/B- trees, or skip-lists or LSM trees. The key structure can be chosen as:
$vertex index
$vertex index_$adjacent vertex index
$vertex index_$vertex attribute
$edge index
...
If graph persistence is desired, B-trees/LSM trees storing key-value pairs of vertices and edges are a good choice.
- Further extending, similar to OLTP using rows as the data model and OLAP using columns as the data model, if vertices or edges have many attributes and there is a need to accelerate the analysis of vertex/edge attributes in the graph, a column storage data model can be used, storing keys as $vertex index_$vertex attribute or $edge index_$edge attribute.
Depth-First Search (DFS) and Breadth-First Search (BFS) of Graphs
Depth-First Search (DFS) of a graph prioritizes visiting successor vertices in the path, similar to post-order traversal of a multi-way tree. Breadth-First Search (BFS) prioritizes visiting all adjacent vertices of the current vertex before visiting secondary adjacent vertices, similar to a fan-out access pattern.
Depth-First Search (DFS)
DFS can be implemented well using recursion to backtrack through vertices. To avoid revisiting the same vertex, a marked_ array is used to mark vertices that have been visited. Complete implementation link.
void DfsPaths::dfs(const UndirectedGraph& G, int v) {
this->marked_[v] = true;
auto pair = G.Adj(v);
std::for_each(pair.first, pair.second, [&, v](const Edge& w){
if (!marked_[w.Dest()]) {
edge_to_[w.Dest()] = v;
dfs(G, w.Dest());
}
});
}
DFS has a time complexity of $O(E+V)$, where each edge is visited once (undirected edges can be considered as bidirectional directed edges), and each vertex is visited once (specifically marked once, with the total number of vertex visits differing only by a constant factor). The space complexity is $O(V)$, used to store the marked_ array and the DFS traversal tree edge_to_.
Breadth-First Search (BFS)
BFS requires a queue to achieve FIFO, where each visited vertex enqueues all its unvisited adjacent vertices. Complete implementation link.
void BfsPaths::bfs(const UndirectedGraph& G, int v) {
std::queue<int> q;
this->marked_[v] = true;
q.push(v);
while (!q.empty()) {
// for a queue, we use front() to get the first element and pop() to remove it
// to avoid "pop" throw out some exceptions
int x = q.front();
q.pop();
auto pair = G.Adj(x);
std::for_each(pair.first, pair.second, [&,x](const Edge& w){
if (!marked_[w.Dest()]) {
edge_to_[w.Dest()] = x;
// mark the vertex before pushing to the queue
marked_[w.Dest()] = true;
q.push(w.Dest());
}
});
}
}
BFS has a time complexity of $O(E+V)$, where each edge is visited once (undirected edges can be considered as bidirectional directed edges), and each vertex is visited once (specifically marked once, with the total number of vertex visits differing only by a constant factor). The space complexity is $O(V)$.
Undirected Graphs
Edges in undirected graphs are bidirectional. They model bidirectional relationships, such as the connection between two components in an electrical system, bidirectional roads, and friendships in social networks.
Cycle Detection
Cycle detection is a common application of graphs, and the method is straightforward—DFS. DFS is essentially a backtracking traversal of a multi-way tree. In cycle detection, we can maintain the current path, and if we find an adjacent vertex already in the path, it indicates that the current path forms a cycle.
In the implementation of cycle detection for undirected graphs, it is important to exclude the starting vertex to avoid false positives. For example, for edge <2, 3>, if DFS visits 3 from 2, 3 may visit 2 again along the original edge <2, 3>, leading to a false positive. Complete implementation link.
void dfs(const UndirectedGraph &g)
{
for (int i = 0; i < g.V(); ++i)
{
if (!has_cycle_ && !marked_[i])
{
// source and destination is itself
dfs_recur(g, i, i);
}
}
}
void dfs_recur(const UndirectedGraph &g, int v, int from)
{
if (has_cycle_)
return;
// add v to path
edge_to_[v] = from;
marked_[v] = true;
auto pair = g.Adj(v);
std::for_each(pair.first, pair.second, [&](const Edge &e)
{
if(has_cycle_) return;
if(!marked_[e.Dest()]) {
dfs_recur(g, e.Dest(), e.Src());
}else if(from != e.Dest()){
// because edge of undirected graph is bidirected,
// so if we find out this edge is not the original edge,
// we know it has a cycle.
// [NOTE]: tricky here, it's better to use the edge_to_ to judge the cycle for more clear intention
// since it's the undirected graph, from != e.Dest() is enough here
has_cycle_=true;
// construct a cycle
edge_to_[e.Dest()]=e.Src();
get_cycle(e.Src());
} });
// revert back
edge_to_[v] = -1;
}
Cycle detection is essentially a DFS, so its time complexity is $O(E+V)$, and space complexity is $O(V)$.
Connected Components
Another interesting property of undirected graphs is connectivity. Since edges in undirected graphs are bidirectional, vertices connected by edges are mutually connected, forming a connected component. For example, the graph below has 3 connected components.
A single DFS can visit all vertices in a connected component, so running DFS on each vertex in the graph can determine the number of connected components. Of course, vertices that have already been visited do not need to run DFS again. Complete implementation link.
void ConnectedComponent::dfs(const UndirectedGraph &G)
{
// run dfs for all vertices, but skip those which have been visited
for (int i = 0; i < G.V(); ++i)
{
if (!marked_[i])
{
++count_;
dfs_recur(G, i);
}
}
}
void ConnectedComponent::dfs_recur(const UndirectedGraph &G, int v)
{
marked_[v] = true;
index_[v] = count_;
auto pair = G.Adj(v);
std::for_each(pair.first, pair.second, [&](const Edge &w)
{
if(!marked_[w.Dest()]) {
dfs_recur(G, w.Dest());
} });
}
Detecting connected components is essentially the same as running a single DFS on a connected graph. The time complexity is $O(E+V)$, and the space complexity is $O(V)$.
Directed Graphs
Edges in directed graphs are unidirectional, meaning they only go from the starting vertex to the ending vertex without a reverse direction. Therefore, directed graphs study reachability, not connectivity. They model unidirectional relationships, such as followers to idols in social networks or subordinates reporting to superiors in a workplace.
Cycle Detection and DAG (Directed Acyclic Graph)
Cycle detection in directed graphs is similar to undirected graphs, achieved by checking for path loops in the current path. A directed graph without cycles is called a DAG (Directed Acyclic Graph). DAGs are widely used in task scheduling because they can provide a topological order that satisfies all precedence constraints, allowing tasks to be scheduled sequentially.
The implementation of cycle detection is as follows, complete implementation link.
void dfs(const Digraph &G)
{
for (int i = 0; i < G.V() && !has_cycle_; ++i)
{
if (!marked_[i])
{
dfs_recur(G, i, i);
}
}
}
void dfs_recur(const Digraph &G, int v, int from)
{
if(has_cycle_) return;
marked_[v] = true;
edge_to_[v]=from;
auto pair = G.Adj(v);
std::for_each(pair.first, pair.second, [&](const Edge &e)
{
if(has_cycle_) return;
if(!marked_[e.Dest()]) {
dfs_recur(G, e.Dest(), e.Src());
}else if(edge_to_[e.Dest()]!=-1){
// hit the cycle
has_cycle_=true;
// construct the cycle
edge_to_[e.Dest()]=e.Src();
get_cycle(e.Src());
} });
edge_to_[v]=-1;
}
Cycle detection in directed graphs also involves running a single DFS. The time complexity is $O(E+V)$, and the space complexity is $O(V)$.
DAG and Topological Sort
A DAG is an abstraction of relationships without cyclic dependencies. For example, multiple tasks may depend on each other, and we need to determine how to schedule the tasks to satisfy all dependencies. This problem is known as precedence-constrained scheduling.
 More intuitively, it can be seen as arranging vertices so that all directed edges point in one direction, satisfying all precedence constraints. This order is called a topological sort.
More intuitively, it can be seen as arranging vertices so that all directed edges point in one direction, satisfying all precedence constraints. This order is called a topological sort.
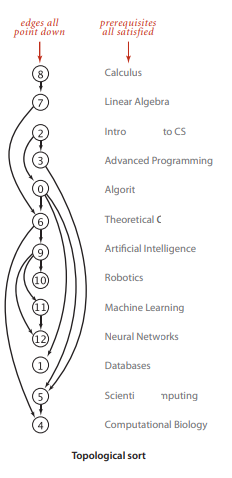
The difficulty in obtaining a topological sort lies in capturing the order relationships among all adjacent vertices of a vertex. At least one DFS pre-order can only capture the order relationship between parent and child vertices, but not between sibling vertices. For example:
[TODO] graph
<1, 2>
<1, 3>
<2, 3>
<3, 4>
possible pre-order DFS: 1 -> 3 -> 4 -> 2
we need topological sort: 1 -> 2 -> 3 -> 4
To solve this problem and capture the order relationships among all adjacent vertices of a vertex, we can observe an interesting property of DFS, which is its post-order traversal. For example:
[TODO] graph
<A, B>
<A, C>
<B, C>
<C, D>
For a graph where there is a directed relationship among the adjacent vertices of A, the post-order traversal output is from back to front. Therefore:
- If we first visit <A, B>, we will continue to visit <B, C> and <C, D>, resulting in a post-order output of {D, C, B, A}.
- If we first visit <A, C>, we will continue to visit <C, D>, then backtrack to visit <B, C>, resulting in a post-order output of {D, C, B, A}.
We can see that the post-order traversal, which visits child nodes before the node itself, naturally outputs the directed dependency relationships among nodes. The final output is the reversed post-order traversal, which needs to be reversed again to obtain the topological sort.
void dfs(const Digraph &g)
{
for (int i = 0; i < g.V() && !has_cycle_; ++i)
{
if (!marked_[i])
dfs_recur(g, i);
}
if (!has_cycle_)
reverse_order();
else
post_order_.clear();
}
void dfs_recur(const Digraph &g, int v)
{
if (has_cycle_)
return;
marked_[v] = true;
path_[v] = true;
auto pair = g.Adj(v);
std::for_each(pair.first, pair.second, [&](const Edge &e)
{
if(has_cycle_) return;
if(!marked_[e.Dest()]) {
dfs_recur(g, e.Dest());
}else if(path_[e.Dest()]) {
has_cycle_=true;
} });
// reverse back
path_[v] = false;
// postorder traversal
post_order_.push_back(v);
}
void reverse_order()
{
std::vector<int> tmp(post_order_.size());
std::reverse_copy(post_order_.begin(), post_order_.end(), tmp.begin());
post_order_.swap(tmp);
}
The Topological Sort algorithm is essentially a DFS. Its time complexity is $O(E+V)$, and the space complexity is $O(V)$.
Transitive Closure
Transitive closure is a mathematical concept that refers to finding the smallest transitive relation containing a given relation on a set $X$. In terms of a graph, it means that if there is a path from vertex $i$ to vertex $j$ in the original graph, then there should be a direct edge from $i$ to $j$ in the transitive closure graph.
So essentially, transitive closure discusses the reachability of vertex pairs in a directed graph. If any two vertices are reachable, there should be a corresponding edge in the transitive closure graph.
Unlike undirected graphs, whose transitive closure can be well represented by connected components or Union-Find algorithms due to the bidirectional nature of edges, the transitive closure problem in directed graphs is more complex. For example:
1 -> 2 -> 3
A single DFS starting from 1 can determine that {1, 2}, {1, 3}, and {2, 3} are reachable, but it cannot determine whether {2, 1} and {3, 1} are reachable.
A brute-force solution can solve this problem by running DFS from each vertex, thus determining all-pairs reachability. Complete implementation link.
TransitiveClosure(const Digraph &g)
{
for (int i = 0; i < g.V(); ++i)
dfs_.push_back(DirectDFS(g, i));
}
bool Reachable(int v, int w) const
{
return dfs_[v].Connected(w);
}
The transitive closure can also be represented using a $V*V$ matrix, which is essentially the same as the above implementation. Each row in the matrix corresponds to the marked_ array in the DirectDFS class.
The time complexity of the DFS version of the transitive closure is $O(V*(E+V))$, and the space complexity is $O(V^{2})$.
For dense graphs, using an adjacency matrix $graph[V][V]$ to represent the graph, the reachability can be determined by traversing all intermediate vertices between any two vertices. This is essentially a brute-force traversal, known as the Floyd-Warshall Algorithm. The time complexity is $O(V^{3})$, and the space complexity is $O(V^{2})$. Code source.
/* Add all vertices one by one to the
set of intermediate vertices.
---> Before start of a iteration,
we have reachability values for
all pairs of vertices such that
the reachability values
consider only the vertices in
set {0, 1, 2, .. k-1} as
intermediate vertices.
----> After the end of a iteration,
vertex no. k is added to the
set of intermediate vertices
and the set becomes {0, 1, .. k} */
for (k = 0; k < V; k++)
{
// Pick all vertices as
// source one by one
for (i = 0; i < V; i++)
{
// Pick all vertices as
// destination for the
// above picked source
for (j = 0; j < V; j++)
{
// If vertex k is on a path
// from i to j,
// then make sure that the value
// of reach[i][j] is 1
reach[i][j] = reach[i][j] ||
(reach[i][k] && reach[k][j]);
}
}
}
Strongly Connected Components (SCC)
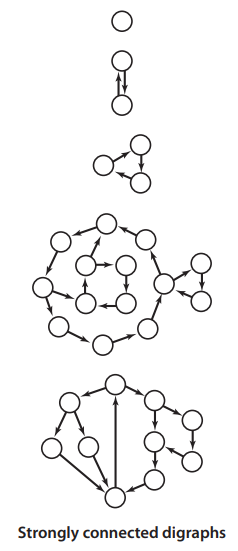
Similar to connected components in undirected graphs, directed graphs also have the concept of strongly connected components. Since edges in directed graphs are unidirectional, a strongly connected component must form a cycle to achieve mutual reachability. The following diagram shows strongly connected components with different numbers of vertices, where a single vertex itself is also a strongly connected component.
Specifically, we can view a strongly connected component as a large vertex, allowing the entire graph to be described as a DAG of normal vertices and large vertices. This large vertex may bring some convenience in information compression and model building.
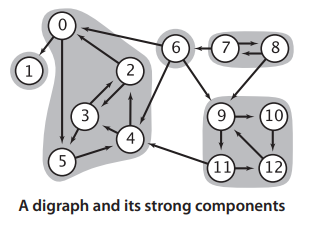
Returning to solving strongly connected components, we can see from the above diagram that if the DFS traversal starts from vertex 1, it cannot visit the nearest strongly connected component {0,2,3,4,5}. If the DFS traversal starts from vertex 2, it can traverse the entire strongly connected component {0,2,3,4,5}, but it cannot identify some non-strongly connected component vertices, failing to distinguish between vertex 1 and vertex 0. Therefore, we need to solve this problem.
First, we observe some characteristics of graphs with strongly connected components:
- Viewing a strongly connected component as a large vertex, the entire graph can be described as a DAG;
- Vertices within a strongly connected component are mutually reachable, so a single DFS can mark all vertices within a strongly connected component;
- Reversing the direction of edges within a strongly connected component still results in a strongly connected component;
To solve the problem of distinguishing strongly connected component vertices from non-strongly connected component vertices during DFS traversal, an important idea is: If we can know the directed relationships between vertices in advance, we can visit the successor vertex of a strongly connected component first, then visit the strongly connected component vertices, thus distinguishing different types of vertices through visit marks.
For example, in the above diagram, visiting vertex 1 first, then vertex 2, allows the DFS starting from vertex 2 to traverse the entire strongly connected component without visiting vertex 1, as vertex 1 has already been visited. It also won’t visit vertex 6, as the entire strongly connected component {0,2,3,4,5} is not reachable to 6.
How can we know the directed relationships between vertices in advance?
As mentioned earlier, a strongly connected component can be abstracted as a large vertex because its internal vertices are mutually reachable. The entire graph is essentially a DAG, and the topological sort of a DAG represents the precedence constraints between vertices. In this scenario, we need the reverse topological sort, as we need to start from the successor vertex, not the precedence vertex.
The algorithm idea is very clear, but the implementation still faces challenges: The actual graph has cycles, not a DAG, so we cannot compute the DAG topological sort.
Here, we need to understand a detail: computing the DAG topological sort itself is just a DFS post-order traversal. Any graph can be traversed entirely by DFS, but the post-order traversal of an acyclic DAG can express the properties of a topological sort.
Therefore, we can still run a DFS post-order traversal on a directed graph with strongly connected components. However, its reverse post-order is not a topological sort. For example, running a DFS post-order traversal on the above graph may result in a partial post-order of {3, 2, 4, 5, 1, 0}, and the reverse partial post-order is {0, 1, 5, 4, 2, 3}, which does not meet our requirement of visiting vertex 1 first. The reason is that DFS on the original graph cannot control the order of visiting adjacent vertices.
[TODO] graph
To avoid visiting non-strongly connected component adjacent vertices, we need to:
- Reverse the directed relationships from non-strongly connected component adjacent vertices to strongly connected component vertices, i.e., reverse the graph;
- Run a DFS post-order traversal on the reversed graph. Since the strongly connected component {0,2,3,4,5} is still a strongly connected component in the reversed graph, but it is not reachable to vertex 1, the reverse partial post-order will satisfy {1, any sequence in {0,2,3,4,5}};
- Perform DFS on the original graph according to the reverse partial post-order of the reversed graph to find all strongly connected components;
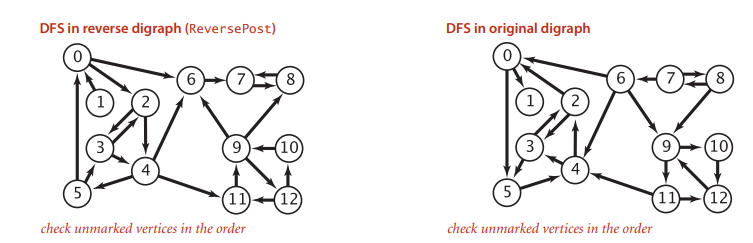
This is the KosarajuSCC algorithm, complete implementation link.
KosarajuSCC(const Digraph& g): marked_(g.V(), false), id_(g.V(), 0), count_(0){
std::vector<int> reverse_order(g.V());
// 1,2: get reverse postorder traversal result of reverse graph
dfs_reverse_graph(g, reverse_order);
// 3: traverse the origin graph according to the reverse_order
dfs_graph(g, reverse_order);
}
void dfs_reverse_graph(const Digraph& g, std::vector<int>& reverse_order) {
Digraph reverse_g=g.Reverse();
std::vector<int> post_order;
dfs(reverse_g, post_order);
std::reverse_copy(post_order.begin(), post_order.end(), reverse_order.begin());
}
void dfs(const Digraph& g, std::vector<int>& post_order) {
for(int i=0; i<g.V(); ++i) {
if(!marked_[i]) {
dfs_recur(g, i, post_order);
}
}
}
void dfs_recur(const Digraph& g, int v, std::vector<int>& post_order) {
marked_[v]=true;
auto pair=g.Adj(v);
std::for_each(pair.first, pair.second, [&](const Edge& e){
if(!marked_[e.Dest()]) {
dfs_recur(g, e.Dest(), post_order);
}
});
// post order traversal
post_order.push_back(v);
}
void dfs_graph(const Digraph& g, const std::vector<int>& reverse_order) {
std::fill(marked_.begin(), marked_.end(), false);
for(int i: reverse_order) {
if(!marked_[i]) {
// a new strongly connected component here
++count_;
dfs_recur(g, i);
}
}
}
void dfs_recur(const Digraph& g, int v) {
marked_[v]=true;
// all nodes in a strongly connected component will be reachable to each other
id_[v]=count_;
auto pair=g.Adj(v);
std::for_each(pair.first, pair.second, [&](const Edge& e){
if(!marked_[e.Dest()]) {
dfs_recur(g, e.Dest());
}
});
}
The time complexity of the KosarajuSCC algorithm is $O(E+V)$, where reversing the graph has a time complexity of $O(E+V)$, computing the topological sort has a time complexity of $O(E+V)$, and the DFS on the original graph has a time complexity of $O(E+V)$. The space complexity is $O(V)$.
Minimum Spanning Tree (MST) for Undirected Graphs
A spanning tree of a connected graph is a tree that includes all the vertices of the graph. For example, the black edges in the following tree form a spanning tree of the undirected graph.
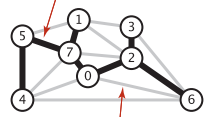 The spanning tree has some very obvious properties:
The spanning tree has some very obvious properties:
- All vertices in the graph are connected by the edges of the tree;
- The number of edges in the spanning tree is (V-1);
- Adding any edge will form a cycle in the spanning tree;
The spanning tree of an undirected graph studies the connectivity of the undirected graph. An undirected graph can have multiple spanning trees. For example, choosing the <5-1> edge in the above graph and removing the <5-7> edge will result in another spanning tree.
[TODO] graph
The minimum spanning tree problem studies the spanning tree with the minimum total edge weight in a weighted undirected graph.
This problem plays a very important role in the field of graph connectivity research. For example, in the field of circuits, it studies how to use the least number of wires to connect all components. In the field of infrastructure, it studies how to pave the least amount of cement roads to connect all villages.
This problem has developed very mature algorithms such as PrimMST and KruskalMST, which can solve the problem in Time Complexity $O(ElogV)$ and $O(ElogE)$ respectively, and even more complex algorithms like Fredman-Tarjan $O(E+VlogV)$ and Chazelle nearly $O(E)$.
The minimum spanning tree problem for directed graphs is called the minimum cost arborescence problem.
Cut Property
Both PrimMST and KruskalMST algorithms are based on the Cut property.
The concept of Cut property is easy to understand. Imagine the graph as a cake. Cutting the cake into two parts in any way (not necessarily into two equal halves) is called a Cut. More rigorously, dividing the vertices of the graph into two non-empty disjoint sets is called a Cut. The edges connecting the two non-empty disjoint sets are called crossing edges.
In the following figure, the division of gray and white vertex sets is a valid Cut, and the red edges are the crossing edges.
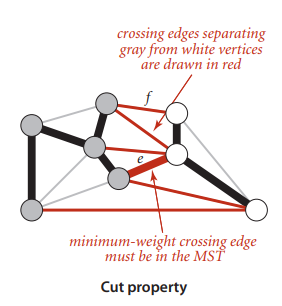
The reason for studying Cut and crossing edges is that for a specific spanning tree, a crossing edge of a Cut must be an edge of the spanning tree, because the crossing edge determines the connectivity of the two non-empty disjoint sets.
For the minimum spanning tree problem, the crossing edge with the smallest weight in a Cut must be an edge of the MST (Minimum Spanning Tree), because it can be easily proven by contradiction that choosing the smallest crossing edge in a Cut always results in a spanning tree with a smaller total edge weight.
The difference between PrimMST and KruskalMST algorithms lies in how they choose the smallest crossing edge.
PrimMST Algorithm
The way PrimMST algorithm chooses the smallest crossing edge is very natural: Starting from a single vertex Cut, adding a new MST vertex in each round, adding new crossing edges, and forming a new Cut.
[TODO] graph
The Cut of a single vertex is simple. The adjacent edges of the starting vertex form the crossing edge set of the Cut. Choosing the smallest crossing edge from it is an effective edge of the minimum spanning tree, and the other vertex of the edge is a new MST vertex. This is determined by the property of any Cut mentioned in the previous section.
Adding all adjacent edges of the new MST vertex to the previous edge set forms a new crossing edge set, and then choosing the smallest crossing edge from it. By obtaining a new MST vertex in each round and constructing a new crossing edge set, we can ensure that we have obtained the complete MST after obtaining V-1 crossing edges.
- Lazy PrimMST Algorithm
The above method is our Lazy PrimMST algorithm. It is called lazy because it delays filtering out some non-crossing edges. For example:
[TODO] graph
graph edge:
<src, dst, weight>
<1, 2, 2.1>
<1, 4, 5.1>
<2, 4, 1.1>
start MST vertex: 1
Round1:
pre MST vertices set: {1}
crossing edge set: {<1, 2, 2.1>, <1, 4, 5.1>}
choose: <1, 2, 2.1>
MST edge set: {<1, 2, 2.1>}
Round2:
pre MST vertices set: {1, 2}
crossing edge set: {<1, 4, 5.1>, <2, 4, 1.1>}
choose: <2, 4, 1.1>
MST edge set: {<1, 2, 2.1>, <2, 4, 1.1>}
Round3:
pre MST vertices set: {1, 2, 4}
crossing edge set: {<1, 4, 5.1>}
choose: <1, 4, 5.1> // NOT LEGAL !!!
// Because <1, 4, 5.1> is not crossing edge anymore,
// its start vertex and end vertex don't belong to different disjoint vertices set.
The Lazy PrimMST algorithm is implemented as follows, complete implementation link.
LazyPrimMST(const UndirectedGraph &g) : marked_(g.V(), false), mst_weight_(0.0)
{
// initialize and build a cut
visit(g, 0);
while (!pq_.empty() && !finished())
{
auto e = pq_.top();
pq_.pop();
// There are some edges which are put into the queue before, but
// are not crossing edges anymore, just ignore them.
if (!marked_[e.Dest()])
{
mst_.push_back(e);
mst_weight_ += e.Weight();
visit(g, e.Dest());
}
}
}
void visit(const UndirectedGraph &g, int v)
{
marked_[v] = true;
auto pair = g.Adj(v);
// scan all adjacent edges of v
// ignore the non-crossing edges here if possible
std::for_each(pair.first, pair.second, [&](const Edge &e)
{ if(!marked_[e.Dest()]) pq_.push(e); });
}
Due to the existence of non-crossing edges, the number of edges in the priority queue may reach $O(E)$ level, so the time and space complexity of the Lazy PrimMST algorithm are: Time Complexity: $O(E*logE)$, Space Complexity: $O(E)$.
For sparse graphs, the time complexity of the Lazy PrimMST algorithm is acceptable, and the implementation is relatively simple. For dense graphs, where E reaches millions or tens of millions, special handling of non-crossing edges is required, which is the PrimMST algorithm.
- PrimMST Algorithm
Since the smallest crossing-edge is chosen to be added to the MST each time, for the priority queue, only the edges with the smallest weight from non-MST vertices to MST vertices need to be maintained, as they are the only ones that may be chosen. For example:
Exist edges:
<1, 2, 5.1>
<1, 3, 2.1>
<3, 2, 1.0>
start MST vertex: 1
Round1:
pre MST vertex set: {1}
crossing edge set: {<1, 2, 5.1>, <1, 3, 2.1>}
choose: <1, 3, 2.1>
MST edge set: {<1, 3, 2.1>}
Round2:
pre MST vertex set: {1, 3}
we find that weight(1->3->2) < weight(1->2), so we replace <1, 2, 5.1> with <3, 2, 1.0>
crossing edge set: {<3, 2, 1.0>}
choose: <3, 2, 1.0>
MST edge set: {<1, 3, 2.1>, <3, 2, 1.0>}
The implementation of the PrimMST algorithm relies on IndexPriorityQueue, a variant of PriorityQueue that supports associating each key with an external index to directly modify the PriorityQueue key based on the external index and then adjust to maintain the heap property. Complete implementation link.
PrimMST(const UndirectedGraph &g) : edge_to_(g.V()), marked_(g.V(), false),
weight_to_(g.V(), std::numeric_limits<double>::infinity()), mst_weight_(0.0), pq_(g.V())
{
// the distance of initial vertex 0 to the mst is 0
weight_to_[0] = 0.0;
pq_.Insert(0, 0.0);
while (!pq_.IsEmpty())
{
mst_weight_ += pq_.Top();
auto i = pq_.Pop();
// visit the new mst vertices
visit(g, i);
}
make_mst();
}
void visit(const UndirectedGraph &g, int v)
{
marked_[v] = true;
auto pair = g.Adj(v);
std::for_each(pair.first, pair.second, [&](const Edge &e)
{
// ignore all non-crossing edges
if(!marked_[e.Dest()]) {
// update non-tree vertex if the new-added vertex has a shorter path to mst
if(e.Weight() < weight_to_[e.Dest()]) {
weight_to_[e.Dest()]=e.Weight();
// edge_to_ will converge to the mst
edge_to_[e.Dest()] = e;
if(pq_.ContainsIndex(e.Dest())) pq_.Change(e.Dest(), e.Weight());
else pq_.Insert(e.Dest(), e.Weight());
}
} });
}
Since the priority queue only maintains the smallest edge weight from non-tree vertices to MST vertices, the space complexity is $O(V)$.
The time complexity is $O(E*logV)$, as the number of updates to the priority queue is $O(E)$, and each heap adjustment is $O(logV)$.
KruskalMST Algorithm
The KruskalMST algorithm chooses the smallest crossing edge by continuously selecting the minimum weight edge from all edges and determining whether it is a crossing edge to decide if it belongs to the MST. The way to determine if an edge is a crossing edge is that its two vertices cannot both belong to the MST vertices.
The correctness of this algorithm can also be proven by contradiction: if an edge is already the minimum crossing edge among all edges, it must be the minimum crossing edge in some Cut, and it must belong to the MST.
The algorithm implementation is as follows, relying on the Union-Find algorithm to determine if an edge is a crossing edge. Complete implementation link.
KruskalMST(const UndirectedGraph& g): pq_(g.Edges().first, g.Edges().second), uf_(g.V()), mst_weight_(0.0) {
while(!pq_.empty() && mst_edges_.size() < g.V()-1) {
auto e = pq_.top();
pq_.pop();
if(!uf_.Connected(e.Dest(), e.Src())) {
mst_edges_.push_back(e);
uf_.Union(e.Dest(), e.Src());
}
}
}
The time complexity of the KruskalMST algorithm is $O(E*logE)$, where Union-Find can perform Connected and Union operations in nearly $O(1)$ time, and each heap adjustment has a time complexity of $O(logE)$, with $O(E)$ adjustments.
The space complexity is $O(E)$, as the number of edges stored in the priority queue is $O(E)$.
Directed Acyclic Graph (DAG) and AcyclicSP Algorithm
When there are negative weights in the graph, the DijkstraSP algorithm cannot be used because the distance from the intermediate vertex to the source vertex is not increasing, so using a greedy algorithm to select the closest vertex to the source vertex as the SPT vertex in each round cannot provide theoretical guarantees.
This section discusses solving the Shortest Path in a DAG with negative weights. A very important feature of a DAG is that a DAG can obtain a topological order, which reflects the dependency relationships between vertices. By relaxing vertices according to the topological order, we can rely on the chain derivation relationship to know that all possible distances from the current vertex to the source vertex have been calculated once, and all precedence vertices have also been calculated once, and all pre-precedence vertices have also been calculated once… For example:
Exist edges:
<1, 2, 1.0>
<2, 3, 1.0>
<3, 4, 1.0>
<1, 4, 5.0>
For this graph, its topological order is {1, 2, 3, 4},
so we can get the minimum dist from 1 to 4 is 3, not 5,
because we know that after relaxing vertex 3,
no other vertex can relax the dist from 1 to 4.
If we relax the vertex in the order {1, 2, 4, 3},
then we may think that the minimum dist from 1 to 4 is 5,
because we have no idea when we can get the minimum dist in a casual relax sequence.
The implementation based on the DAG topological order is as follows, complete implementation link.
AcyclicSP(const Digraph &g, int s) : src_(s), edge_to_(g.V()), dist_to_(g.V(), std::numeric_limits<double>::infinity())
{
dist_to_[s] = 0.0;
// calculate Topological sort
Topological tp(g);
if (!tp.IsDAG())
return;
relax_all(g, tp.Order());
}
void relax_all(const Digraph &g, const std::vector<int> &vs)
{
int st = 0;
// skip precedence vertices to src_
// they are all unreachable
for (; st < (int)vs.size(); ++st)
{
if (vs[st] == src_)
break;
}
for (; st < (int)vs.size(); ++st)
{
auto pair = g.Adj(vs[st]);
std::for_each(pair.first, pair.second, [&](const Edge &e)
{ relax(e); });
}
}
void relax(const Edge &e)
{
double dist = dist_to_[e.Src()] + e.Weight();
if (dist < dist_to_[e.Dest()])
{
dist_to_[e.Dest()] = dist;
edge_to_[e.Dest()] = e;
}
}
The AcyclicSP algorithm has a time complexity of $O(E+V)$, where calculating the DAG topological order has a time complexity of $O(E+V)$, and relaxing vertices based on the topological order has a time complexity of $O(E+V)$. The space complexity of the AcyclicSP algorithm is $O(V)$.
General Graph and Bellman-FordSP Algorithm
The above discussion covers some special graph shortest path solutions, where the DijkstraSP algorithm relies on non-negative weights, and the AcyclicSP algorithm relies on a DAG. For graphs with both positive and negative weights and the presence of positive and negative cycles, a more general Bellman-Ford algorithm is needed.
For solving the shortest path problem, the presence of positive cycles does not affect the result, so we do not consider positive cycles. If a negative cycle is reachable from the source vertex, all vertices on the negative cycle cannot construct the shortest path because a shorter path can always be constructed along the negative cycle.
For a general graph, we define the shortest path as:
- If the source vertex is unreachable, there is no shortest path, and the distance is positive infinity.
- If the source vertex is reachable, but it is a vertex on a negative cycle, there is no shortest path, and the distance is negative infinity.
- If the source vertex is reachable, and it is not a vertex on a negative cycle, there is a simple shortest path.
The Bellman-Ford algorithm is based on this intuition: For a directed graph without a negative cycle reachable from the source vertex, relaxing all edges in any order in each round will obtain at least one SPT vertex. After V-1 rounds, the SPT will be obtained.
This intuition may seem unreasonable at first glance, so let’s consider a shortest path: s -> v1 -> v2 -> v3 -> t For the Bellman-Ford algorithm, if s -> v1 -> v2 is found in round i, then v3 can be found in round i+1 by relaxing edges in any order.
This conclusion is valid because in round i+1, relaxing edges in any order will not change s -> v1 -> v2 since they are already the shortest paths. When relaxing the adjacent edges of v2, dist_to[v3] will be updated to dist_to[v2] + weight(v2, v3), which is the minimum value of dist_to[v3] because we assumed the existence of the shortest path s -> v1 -> v2 -> v3 -> t.
Even if there is a shorter path v2 -> v4 -> v3, v4 can be found in round i+1, and v3 can be found in round i+2. This does not contradict our initial assumption, but it illustrates that the principles are the same.
The Bellman-Ford algorithm can be considered a brute-force solution, theoretically proving that relaxing edges in any order can obtain the SPT after V-1 rounds. If a negative cycle reachable from the source vertex exists, it cannot end after V-1 rounds, so the existence of a negative cycle in the original graph can be detected after V-1 rounds.
- Lazy Bellman-FordSP Algorithm
The above description is the Lazy Bellman-FordSP algorithm, which includes the source vertex and directly performs V rounds of relaxation. Complete implementation link.
LazyBellmanFordSP(const Digraph &g, int s) : src_(s), edge_to_(g.V()), dist_to_(g.V(), std::numeric_limits<double>::infinity())
{
dist_to_[s] = 0.0;
// for any digraph without negative cycles, it will converge to spt after V rounds
for (int r = 0; r < g.V(); ++r)
{
for (int v = 0; v < g.V(); ++v)
{
auto pair = g.Adj(v);
std::for_each(pair.first, pair.second, [&](const Edge &e)
{
if(e.Weight()+dist_to_[e.Src()] < dist_to_[e.Dest()]) {
edge_to_[e.Dest()]=e;
dist_to_[e.Dest()]=e.Weight()+dist_to_[e.Src()];
} });
}
}
findNegativeCycle();
}
void findNegativeCycle()
{
std::vector<bool> marked(edge_to_.size(), false);
int negative_cycle_vertex = -1;
for (int i = 0; i < (int)edge_to_.size() && !has_negative_cycle_; ++i)
{
if (marked[i])
continue;
int w = i;
while (w != -1)
{
marked[w] = true;
w = edge_to_[w].Src();
if (w == i)
{
has_negative_cycle_ = true;
negative_cycle_vertex = i;
break;
}
}
}
if (has_negative_cycle_)
{
// get negative cycle
int w = negative_cycle_vertex;
while (edge_to_[w].Src() != negative_cycle_vertex)
{
negative_cycle_.push_back(edge_to_[w]);
w = edge_to_[w].Src();
}
negative_cycle_.push_back(edge_to_[w]);
}
}
The Lazy Bellman-FordSP algorithm has a time complexity of $O(E*V)$, where $O(V)$ rounds are needed, and each round requires relaxing $O(E)$ edges. The space complexity is $O(V)$.
- Bellman-FordSP Algorithm
A more efficient Bellman-FordSP algorithm only uses vertices updated in the previous round for relaxation because only their adjacent edges will cause other vertices’ distances to the source vertex to be updated.
The specific implementation is as follows, complete implementation link.
BellmanFordSP(const Digraph &g, int s) : src_(s), edge_to_(g.V()), dist_to_(g.V(), std::numeric_limits<double>::infinity()), on_que_(g.V(), false)
{
dist_to_[s] = 0.0;
on_que_[s] = true;
// start from the source vertex
que_.push(s);
int round=0;
while (!que_.empty())
{
int v = que_.front();
que_.pop();
on_que_[v] = false;
auto pair = g.Adj(v);
std::for_each(pair.first, pair.second, [&](const Edge &e)
{
if(e.Weight()+dist_to_[e.Src()] < dist_to_[e.Dest()]) {
edge_to_[e.Dest()]=e;
dist_to_[e.Dest()]=e.Weight()+dist_to_[e.Src()];
// if vertex is not on queue, push it for next round
if(!on_que_[e.Dest()]) {
que_.push(e.Dest());
on_que_[e.Dest()]=true;
}
} });
// a digraph without negative cycles will converge at V rounds
if(++round%g.V()==0) {
findNegativeCycle();
break;
}
}
}
The Bellman-FordSP algorithm generally has a time complexity of $O(E+V)$, where on average, only one vertex will be relaxed in each round, and a total of $O(E)$ edges will be relaxed. The worst-case time complexity is the same as the Lazy Bellman-FordSP algorithm, which is $O(E*V)$. The space complexity is $O(V)$.
Summary
This article covers the basics of common graph algorithms in Algorithms 4. Complete code link.