
Background
I haven’t updated my blog for a long time. Over the past year, I relocated and embarked on a job search journey. This experience was challenging but also enlightening, as it helped me understand the intricacies of the process. The language of this blog will be straightforward. It aims to review a notable system design experience that helped me improve my communication strategies.
Preface
To pick out the key points, I crossed many red lines, including system design and behavioral questions (BQ). While I am glad that I eventually asked the right key question in system design, I did not do so for BQ, which led to some cultural misunderstandings.
I have made mistakes in almost all the system design interviews I have participated in before. This was mainly because I did not understand what kind of answers the interviewers were looking for when asking these types of questions. In the past, if I knew the answers, I did not perform badly. However, if I did not know the answers, I performed poorly and did not understand why. Overall, I felt that I could not lead the entire system design communication process, even though I knew many details of each module.
The core issue is that the way I presented my answers was wrong.
It is similar to solving a LeetCode problem. If the evaluation criteria are the time and space ranking after acceptance (ac), then the best way is to solve the problem directly. But is this the way to do it during an interview? Not really. Coding interviews usually emphasize “problem solving” after the name, and the “problem solving” aspect is very particular. Let’s look at a more reasonable approach to a coding interview:
- Clarify the Problem: When given a relatively vague problem, such as a paraphrase problem, try to explain the problem and confirm whether there is any misunderstanding. Align the vague points by providing examples.
- Define Input and Output: Determine the form of input and output, such as whether they are integers or strings, arrays or single elements, etc.
- Propose Solutions: Propose at least two solutions, analyze their pros and cons, and determine the time and space complexity of different solutions. Walk through the general process with an example, and confirm with the interviewer which solution to implement after ensuring mutual understanding.
- Implementation: Start implementing the solution. Construct normal and abnormal test cases, maintain a reasonable speed, explain while implementing, use reasonable variable names, function names, or comments, and keep the implementation readable and clean.
- Review and Test: After implementation, actively use an example to walk through the entire logic, check and modify minor errors in the implementation process. If possible, run the code, ensure it passes basic use cases, and then discuss with the interviewer what additional test cases can be added. By constructing test cases, check whether the implementation covers abnormal scenarios.
From the above, we can see that although passing the first acceptance (AC) is very important, it is only one step in the process. For a hard-level question, it primarily tests intelligence, making it difficult to assess problem-solving ability. Effective problem-solving involves several specific steps:
- Define the Problem: Start by clarifying a specific function of a vague problem.
- Determine Input and Output: Clearly define the forms of input and output, and establish boundaries.
- Propose Solutions: Offer different solutions, analyze their pros and cons, and ensure mutual understanding. Use examples to clarify if necessary.
- Maintain Communication: Keep continuous and effective communication during implementation. This allows the interviewer to follow your thought process and provide hints if needed.
- Walkthrough Implementation: Review the entire implementation with examples to ensure the basic use cases are handled correctly.
- Discuss Corner Cases: Communicate and discuss possible corner cases to demonstrate the ability to deliver high-quality code.
The above steps showcase problem-solving abilities beyond mere intelligence. Through continuous communication and alignment of understanding, a problem is effectively solved rather than just answered.
Having said that, almost all my previous coding rounds were not done correctly. Unless the interviewer only cares about testing your intelligence or showing his intellectual superiority, skipping the whole process of communication and directly answering a question is essentially a flawed result, because there are usually multiple scoring points for the coding round.
I have been through many coding rounds, most of which were easy/medium, and I also went through whiteboard. I directly answered many questions without realizing this problem. Sometimes I showed some steps in the above process, and the interviewer gave me a high evaluation. This partly shows that they may not necessarily know what specific abilities they are looking for in the candidate, and may simply want to know whether your computer IQ is online.
Reflecting on my past interviews, even with the simplest LRU cache implementation, my answers often fell short. Knowing the standard solution, I would quickly write the accepted (AC) answer without thoroughly defining the input and output types, handling abnormal scenarios (e.g., throwing exceptions or returning -1), or discussing corner cases. This pre-knowledge limited my ability to communicate effectively with the interviewer and demonstrate my problem-solving skills.
Interestingly, I performed well in a coding round with Atlassian. The questions were vague, forcing me to define the problem clearly. The interviewer knew what they were looking for, but I made another mistake. Due to an accent issue, I couldn’t fully understand the interviewer, missing the chance to discuss different solutions or pick up on hints for a better approach. Unfortunately, that opportunity has passed.
Main Topic
Let’s turn our attention to system design. This is a more complex challenge because it involves addressing a vague question that cannot be answered directly. If you don’t realize what kind of abilities you need to demonstrate in system design and instead try to directly provide an answer, the problem becomes even bigger.
The key to system design is not just providing a good solution but demonstrating how you arrived at that solution. This process should showcase your problem-solving abilities, communication skills, and technical expertise.
During my system design interview, I found myself in a passive position and couldn’t understand why. Despite my technical knowledge and engineering experience, I struggled to lead the design discussion.
It became clear that I was missing a crucial element: asking the right questions.
Reflecting on the feedback and my performance, I realized that the interviewers were looking for a specific type of response. They wanted to see how I approached a broad question, how I analyzed the problem, and how I communicated my thought process. This was a moment of enlightenment for me, connecting all my previous learning experiences.
Before diving deeper, there’s another crucial point to address: why hadn’t I realized this issue earlier?
Interestingly, I had prepared extensively for common system design interview questions and practiced with friends. In actual interviews, I performed well on familiar questions but poorly on new ones. This disparity highlighted the importance of asking the right questions during the interview. It wasn’t until an on-site interview, where I faced an entirely new problem and collaboratively worked through a solution, that I received feedback and understood the significance of this approach.
Back to the main topic, I would like to explain further:
System design interviews are inherently complex because they require addressing broad, often ambiguous questions. The key is not just to provide a good solution but to demonstrate the process of arriving at that solution. This involves showcasing your problem-solving abilities, communication skills, and technical expertise.
The critical point is not just to present a good solution but to show the journey of arriving at that solution. This involves demonstrating your analytical skills, effective communication, and continuous improvement based on feedback. Simply providing a final design, like solving a LeetCode problem, is insufficient. The design must be a product of specific requirements, including non-functional aspects like latency and availability.
In summary, the scoring in system design interviews is based on the process, not just the final result.
How do I know the requirements of this interview? It’s very simple, just ask! Effective communication is key. Asking questions until everything is clear is crucial because it demonstrates your understanding of system design. The questions should be asked in a hierarchical manner, addressing functional and non-functional requirements progressively.
The questions you ask directly reflect your engineering understanding.
The critical point is not just to present a good solution but to show the journey of arriving at that solution. This involves demonstrating your analytical skills, effective communication, and continuous improvement based on feedback. Simply providing a final design, like solving a LeetCode problem, is insufficient. The design must be a product of specific requirements, including non-functional aspects like latency and availability.
In summary, the scoring in system design interviews is based on the process, not just the final result.
How do I know the requirements of this interview? It’s very simple, just ask! Effective communication is key. Asking questions until everything is clear is crucial because it demonstrates your understanding of system design. The questions should be asked in a hierarchical manner, addressing functional and non-functional requirements progressively.
The questions you ask directly reflect your engineering understanding.
Let me start with my interview review to illustrate why my interview was unsuccessful.
Problem Definition
This company’s business focuses on making recommendations. The issue arises when a user purchases a service, such as a concert ticket from Ticketmaster, and receives related service recommendations. Sometimes, these recommendations are not appropriate. For instance, if a user is already a 50% discount member of a merchant, recommending a 30% discount plan from the same merchant is pointless. This problem needs to be addressed.
Input and Output
- Input: Advertiser file containing a single column with all registered users of the advertiser.
- Output: An API that sends a GET request to the match service to check if
advertiser+emailhashexists.
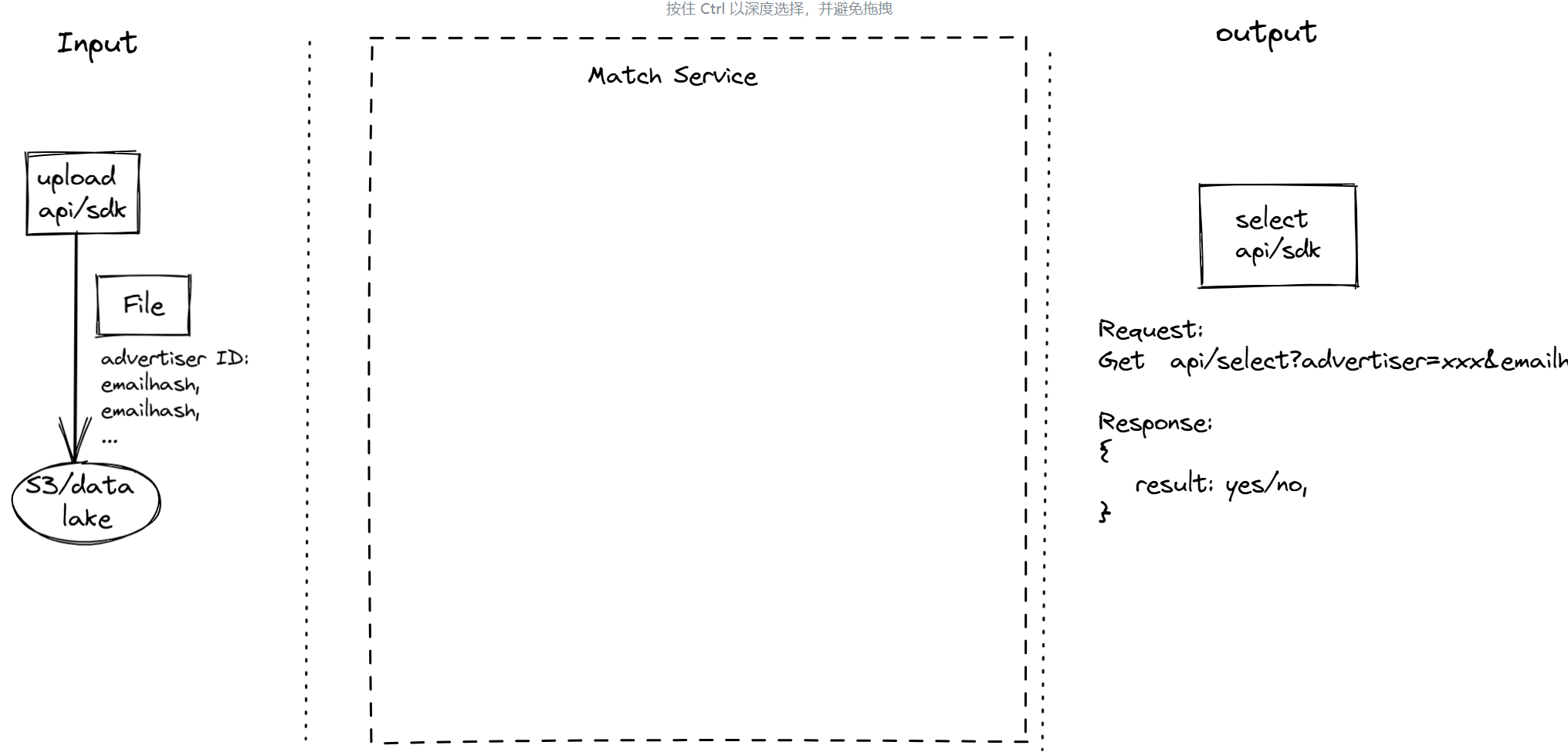
Please start designing!
This is a new design problem, very close to real-world scenarios. Although I haven’t encountered it before, I need to stay calm and proceed with the design.
First, let’s examine the problem. The problem itself is clearly stated, and the input and output are well described.
The input involves checking whether a user is registered as a member. The advertiser’s member list file, stored in a data lake, is required, and the match service needs to retrieve it. The output is an API that queries the match service, which then returns the result.
Since this is a system design problem, the specifics of the data lake are not crucial. What matters is that it can provide metadata and file content.
Now, it’s time to ask questions. The standard starting point is to identify the Functional Requirements and Non-Functional Requirements. The former has been clearly described, so we need to determine the latter:
- What is the scale of the advertiser in the input and the scale of a single file?
- Advertiser: 10k
- Single file size: 10k to 100GB
- Email MD5: 128 bits
- Total number of records after processing: 100GB/16B = 6 GB = 6*10^9 This is crucial because a single file may be very large. The match service needs to provide parallel computing and computing expansion capabilities. The amount of data stored in the intermediate results exceeds the storage capacity of a single MySQL/PostgreSQL machine, so it may be necessary to consider a database such as NoSQL to improve scalability.
- What is the order of magnitude of the RPS of the query in output?
- 10K level
So far, I have finished asking questions in the first stage, mainly focusing on input and output. I believe this is a reasonable approach. There are indeed many more questions to ask, which I will address later. However, I think it’s unnecessary to ask them all at the first stage. By solving the most basic questions first, I can gradually introduce additional questions to maintain effective communication.
Design 1
This is the design I will give next. Considering the existence of super large files, a read service is needed to handle the file metadata. This service will divide the super large file into manageable blocks, such as 64MB each. These blocks will then be passed to a compute pool for parallel reading and processing.
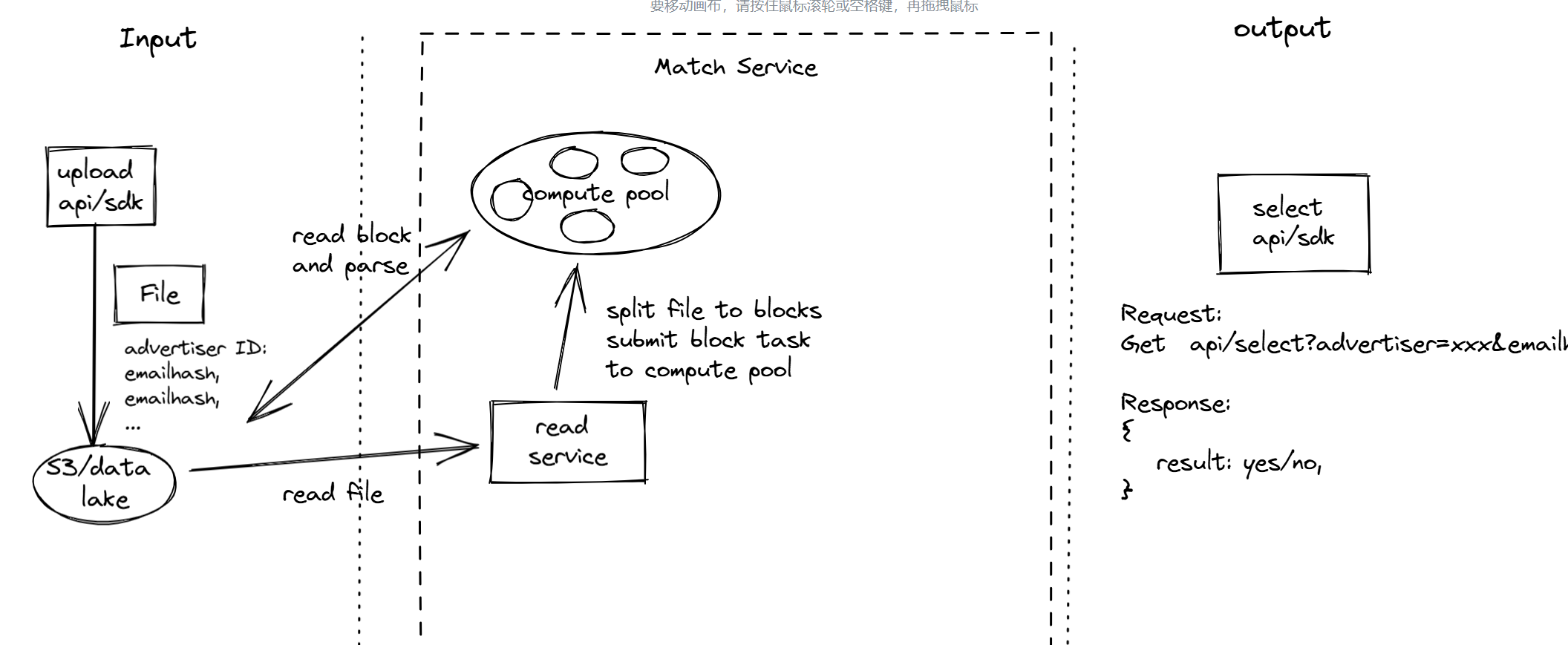
I actually made a mistake here. I delved into details prematurely and should have discussed them later. After presenting my general solution, I faced challenges. From this point, I felt at a disadvantage, possibly deviating from the interviewer’s expected answer. He questioned the functionality of the read service, how it detected new files, why it split files into blocks, why the block size was 64MB, and how to handle data loss due to splitting.
These questions were quite challenging. They stemmed from his previous work experience, where he had thoroughly considered these details and was more familiar with them than I was. When asked a broad question, he felt the details were insufficient and unclear. Additionally, the interviewer made several assumptions, such as assuming I knew the semantic interface provided by the data lake or S3. While I understood the principles of S3, I had never used it, leading to further challenges in my explanation.
A deeper issue here is the inherent inequality between the interviewer and the interviewee. The interviewee must think through a new question from scratch, while the interviewer has already considered it thoroughly. This can lead to the interviewer mistakenly believing that these issues are obvious and should have been anticipated. However, from my perspective, many details require in-depth consideration and adjustment. The real problem was diving into details too early, which was not appropriate.
I responded to his challenge by explaining that I had assumed S3 would store files in blocks, allowing me to directly retrieve block information for processing. However, he didn’t understand my answer because we were both operating on different assumptions. He assumed I knew the data lake’s interface semantics, while I assumed S3 worked in a specific way. After some back-and-forth, we finally aligned. It turned out that the data lake provides the ability to read file metadata directly but does not support reading files in blocks. Instead, it supports reading files from a specific position.
This experience highlights the importance of understanding the interviewer’s assumptions. Everyone makes assumptions, such as assuming the air is breathable or that backgrounds are similar. Interviewers often ask questions to clarify assumptions, but they may also be making their own assumptions. This is human nature.
Regarding the 64MB block size, I explained that it is a reasonable size that can be processed quickly. There isn’t an exact value here; it’s more of a reference point, such as facilitating block alignment within the data lake. There is no standard answer. Concerning the possibility of splitting records in the file, I acknowledged that it could happen. I then noted that each record in the file is an MD5 hash, so they can be aligned, which seemed to satisfy the interviewer. However, there could still be issues. Unless the data is cleaned, abnormal data might cause misalignment after splitting. This is a minor detail that the interviewer considered, but I didn’t, leading to the challenge.
To address the issue of obtaining new files, I introduced a meta service. This service is responsible for detecting new files and distributing them to the read service for segmentation. Initially, I failed to inquire about the semantic interface of the data lake, which was a crucial oversight. It’s essential to ask about the data lake’s capabilities at this stage, such as whether it supports actively pushing new files via pub/sub to a specific directory or through incremental monitoring. This is a fundamental step, and ensuring clear communication about the input/output interface is vital in system design.
Design 2
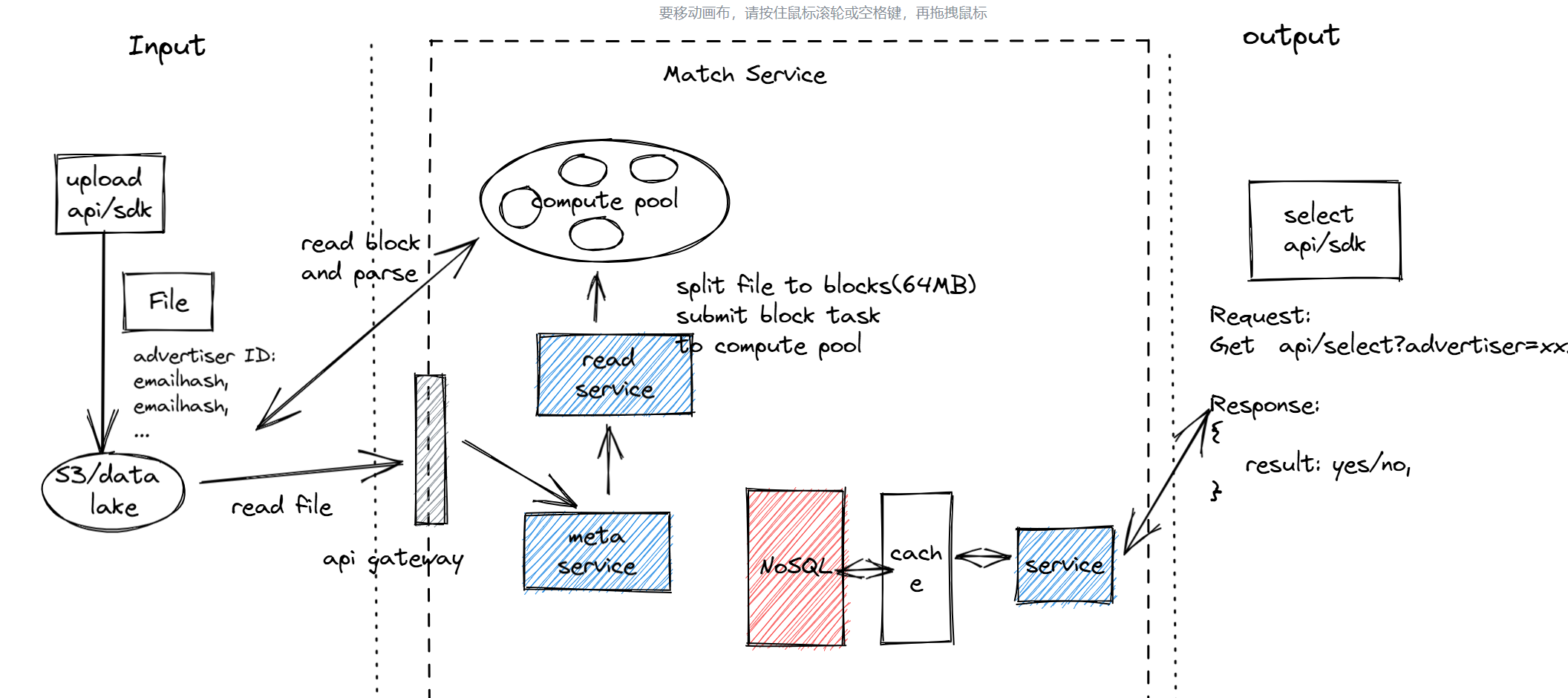
After finishing here, I think I have roughly designed the first part, and then skipped to the design of the latter part. To support output, I added a NoSQL database, cache, and matcher service. I explained that NoSQL is used because there are too many records stored in the middle, and scalability is needed. The cache is to speed up the access rate, and then I explained the DB schema and so on.
This is exactly what I wanted to do: NoSQL + cache + service. But here I started to run into problems again. I was challenged like crazy. Here are some questions:
- Why do we need to add a cache? This is actually a good question. Adding cache to improve interface performance and reduce latency is common sense in engineering design. When asked about the purpose of this, I gave a normal answer, which was obviously not what he wanted. I added that because most data and access in real life naturally follow the 2-8 principle, we need a cache. He then asked why we had to make such an assumption about user access distribution, and why we assumed that we needed to improve API performance. This is the point he wanted to express:
- I don’t have any demand to improve the performance of the API. If you have such a demand, you should communicate with me first. For example, ask me what level the front-end delay of the API query needs to be, such as within 50ms. If it was originally 100ms, it needs to be optimized to within 50ms.
- Why must we add cache? For example, from 100ms to 50ms, why must it be caused by the delay in accessing the storage? Not other modules.
When I was asked this question, I basically knew that the final result would not be good, because I had actually missed a lot of points in system design:
- Without communication, assumptions are made, assuming that API access needs to optimize latency and that latency is caused by storage.
- Talking about system design lacks a sense of hierarchy. There are actually a lot of things to say about cache, but it is a bit inappropriate to talk about it at the beginning. It should be another functional sub-requirement, such as optimizing performance. Note that it is actually another sub-problem, and now I haven’t finished talking about the top-level problem, so I shouldn’t go into it in depth.
To make up for it here, I still talked about some cache-related technical knowledge, such as using the API gateway’s metric to count interface delays, using opentrace to do distributed tracing of the backend system to determine the delay optimization points, and counting the statistical data distribution from the API gateway’s log to determine the optimal cache capacity. For example, the different locations where the cache can be placed (client/CDN/server) and the geo+data locality features, the cache’s read and write methods (read aside/read through/write through, etc.), different cache eviction policies (LRU/LFU/TTL), cache avalanche/penetration and other issues.
I wanted to fully demonstrate the depth of my technical accumulation. In fact, these are all very good topics, but unfortunately some prerequisites were not done well. In the end, his evaluation of this part was also very objective, that is, it was too easy to go into details and the description method was too jumpy.
Reflecting on my past work experience, I realize that my thinking habits were shaped by my role in data infrastructure. The problems I encountered were usually well-defined, and my primary focus was on enhancing scalability, reliability, availability, and performance through design. I didn’t have much opportunity to engage in discussions with PMs or to repeatedly define problems. Performance optimization was a routine task for me, and my success was often measured by the extent of performance improvements. I rarely questioned the necessity of these improvements or the specific needs they addressed. This has highlighted a gap in my approach to problem-solving.
High Availability Design
I thought the design might be finished, but the interviewer continued to challenge me because he had done this before and knew a lot of details. He asked me to describe how the high availability of the entire system is guaranteed. I described that the matcher service is stateless and can be horizontally expanded through the API gateway, and that NoSQL is also horizontally scalable and can be horizontally expanded. It also has a highly available multi-backup design, thus ensuring the high availability of the system. However, I completely ignored the first half of the module in this part, mainly because I didn’t realize that I had skipped the first half without completing the design.
The interviewer drew my attention to the first half and asked me to introduce the high availability design of the meta service, read service, and compute service, and described the data flow of the first half.
After being asked out, I realized that I had lost the initiative in the interview again. The main reason was that I did not explain in a systematic way how the system was designed and how the data flowed in the system design. High availability design is actually another sub-problem. It is a system robustness issue that is considered after the entire system meets the basic functions and the data flow successfully flows from input to output. In fact, performance issues including cache are actually another sub-problem and should be described at another stage.
At this stage, I faced two main challenges:
- Confusion in Description Levels: My explanations lacked clarity and depth, making it difficult to dive into specific details.
- Overlooking Implementation Details: During my system design exercises, I often neglected crucial implementation aspects such as data flow direction, service dependencies, ensuring high availability, and the trade-offs between push and pull mechanisms.
Let’s start by describing the implementation details.
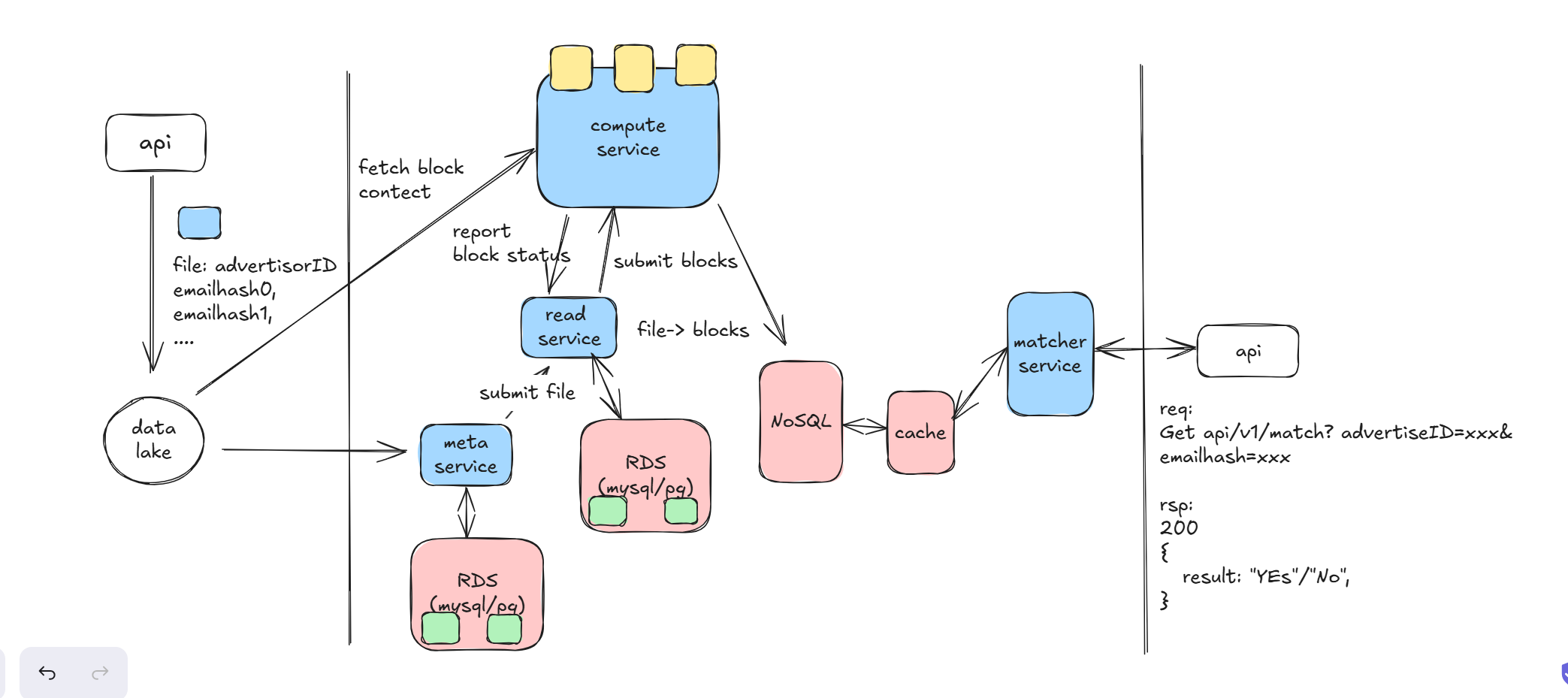
Let me explain the design in this figure. My problem here is that some high-availability designs are based on continuous questioning rather than proactive planning, which is a weak point. Let’s take a closer look:
- The meta service obtains new files by monitoring or periodically scanning the data lake and writes them to the database. Given that the advertiser count is only 10k and the file size is also only 10k, MySQL or PostgreSQL can be used, with master-slave replication for high availability. I only described the high availability of new file storage, not the high availability of the meta service itself. The meta service is essentially a single point and stateless, but we don’t need multiple meta services unless the upstream data volume is very large and requires parallelization by partitioning. To ensure its high availability, it needs hot standby and leader election support, or it can rely on Kubernetes’ automatic failover capability. There are trade-offs here, such as handling potential issues with multiple meta services and ensuring unique key deduplication at the data layer. Personally, I prefer having a master election center in the system, which can also handle pub-sub and service discovery.
- The read service has a straightforward role. The meta service forwards new file information to it, and it is responsible for segmenting and maintaining the metadata {file, [block0, block2, …]}. For its high availability, this information must also be stored in the database. The read service does not need horizontal scaling due to its low computational load, but horizontal scaling through hashing is possible.
- There is a high availability issue here that I didn’t fully consider during the interview because I was new to this problem. This is normal. Reflecting on it now, the data flow goes from the data lake -> meta service -> read service -> compute service. The compute service receives data input, performs computations, and writes the results to NoSQL. Since the input and output are immutable, the failover of a single task can be handled by resubmitting the task.
If the compute service itself has high availability capabilities for tasks, such as automatic failover using a compute engine like Spark or Flink, the read service does not need to handle failover.
For smaller teams without complex computing roles in the system architecture, a process pool or thread pool can be used to implement a simple stateless compute service. In this case, task persistence and failover capabilities should be managed by the read service.
If a compute unit crashes, the read service must detect this and resubmit the task. The read service needs to track the status of each block, so the compute service should support a task feedback mechanism. This can be achieved by providing an RPC callback interface from the read service to the compute service. Additionally, the read service should implement a timeout mechanism to periodically scan the block list and resubmit tasks if a timeout is detected.
In this scenario, the read service can be a single role with hot standby and leader election to ensure high availability, as it has management responsibilities.
We have now discussed the failover capabilities of these services, considering whether they need to be stateless or have management responsibilities. We have also examined high availability from both computing and storage perspectives.
It’s important to note that as we progress through the system design discussion, we will add different interfaces to the services to enhance their functionality.
Module interaction design
I almost missed a detail. The interviewer asked whether the meta service should use push or pull to access the read service. I was a bit confused at first. While I understand the push and pull interaction methods, I had always assumed that push was the standard interaction method between services, so I didn’t think about it in detail. I just described the pros and cons of both methods, which was considered as answering his question.
However, there is a better answer. In this scenario, both push and pull are acceptable.
When we use push, it means we want the upstream message to be sent to the downstream as soon as possible and in a timely manner. There are timeliness issues to consider here (such as sudden notifications) and upstream data security considerations (such as the upstream may crash and lose notifications), so the downstream needs to receive, process, and store it. The downstream can get the message in a short time or store the message to achieve the final consistency of the upstream information.
At the same time, the problem encountered by the downstream is that, due to the high push speed of the upstream, it may need to store messages and persist them; otherwise, the messages will be lost if it crashes. In other words, the push mode basically requires the receiver to have the ability to store messages, and there will be a backpressure mechanism. The receiver needs this negative feedback mechanism to tell the sender that it can’t handle more messages and to send fewer.
A classic example is TCP. When the receiver’s CPU cannot handle the messages and they accumulate in memory, it needs to use the win parameter in the response to tell the sender to send fewer messages next time.
When TiDB CDC receives region raft logs, it uses a push mechanism because the upstream TiDB raft logs have a garbage collection (GC) process. For downstream CDC that relies on raft logs, TiDB needs to send raft log events to CDC as soon as possible. Consequently, CDC requires intermediate storage and will trigger backpressure when it encounters limited processing capacity. This can be observed in the monitoring system, where the rate at which TiDB sends events to CDC may slow down significantly or even drop to zero.
In contrast, the pull mode is straightforward. The data is stored upstream, and the downstream can pull it when it has idle processing capacity. This implementation is simpler.
Another point to consider is that since push will send messages to different downstreams, in some task processing scenarios, it results in multiple downstreams having their own task queues. This can lead to situations where some downstreams with strong processing capabilities have no tasks, while others with weaker capabilities have significant task queues. To address this, you can use the pull method to centralize task queues upstream or implement a task-stealing mechanism to balance the downstream task queues.
In the current scenario, since both the meta service and the read service have persistent storage capabilities and the size of the upstream files is not large, there is not much difference between using push or pull.
Our system design has evolved to this point.
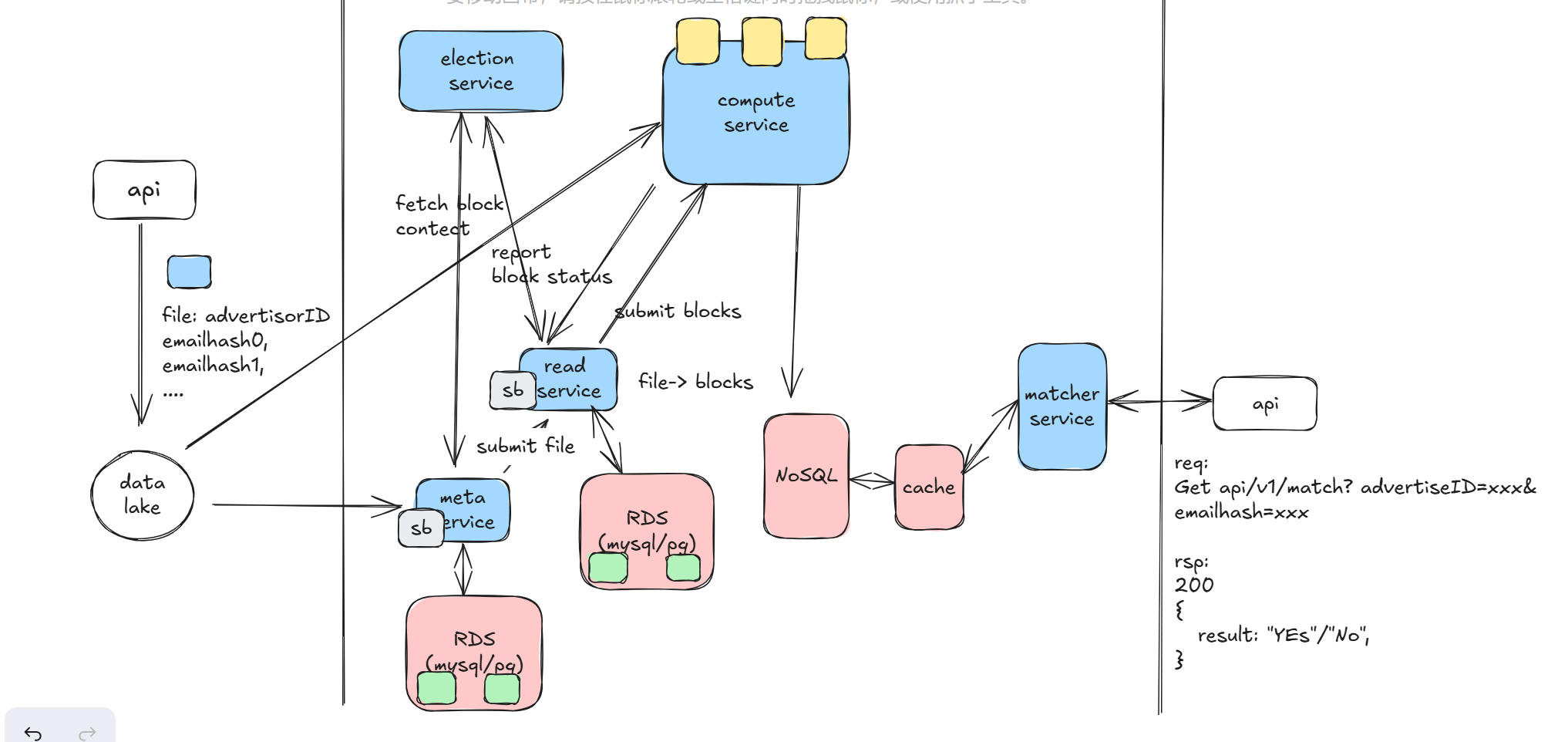
At this point in the design, the system is relatively complete, meeting the basic functions and ensuring high availability.
The next step involves addressing performance issues. This includes analyzing the dataflow path of certain APIs and using caching to optimize latency. Performance discussions can cover cache capacity estimation, the potential use of a CDN, and calculating the optimal storage solution based on CDN storage costs and network retrieval costs. This part requires communication with the interviewer to gauge their interest and to demonstrate your engineering skills proactively.
Expanded functionality
The interviewer posed an interesting question about the end-to-end latency of the system. Specifically, after a customer submits a file to the data lake, how long does it take to query the output API? The underlying concern here is: with limited machine resources, how can we ensure the system’s end-to-end latency meets the PM’s expectations during business peaks? For instance, if the end-to-end latency must be within 2 hours, do customers have different processing priorities?
This is a very meaningful question. Machine resources are limited, and depending on the company’s size and business scenario, the available computing and storage resources are constrained. For this file processing, the computational load required for parallel processing of a 100GB file is substantial, and there might be significant wait times when applying for K8s resources. Another issue is that if one customer submits a 100GB file and another submits a 10K file, the customer with the 10K file might have to wait for the larger file to be processed first. This is unreasonable and could block many customers, leading to numerous end-to-end SLA breaches.
This is a classic problem in architecture. Data and behavior are naturally hierarchical, whether it’s data locality and access locality in computers, or virtual memory mechanisms, cache mechanisms, and the company’s large/medium/small customers. With limited resources, some kind of priority mechanism or round-robin mechanism is needed.
For this scenario, we can set different priorities for different files and use factors like waiting time, customer weight, and file size to update the file priority. In a priority scenario, it is more reasonable for the compute service and read service to use the pull mechanism, only pulling tasks when they are capable of processing. Additionally, the compute service should provide a priority pool mechanism to ensure it is not monopolized by a block task of a very large file, thereby ensuring that smaller files have the opportunity to be processed quickly and preferentially.
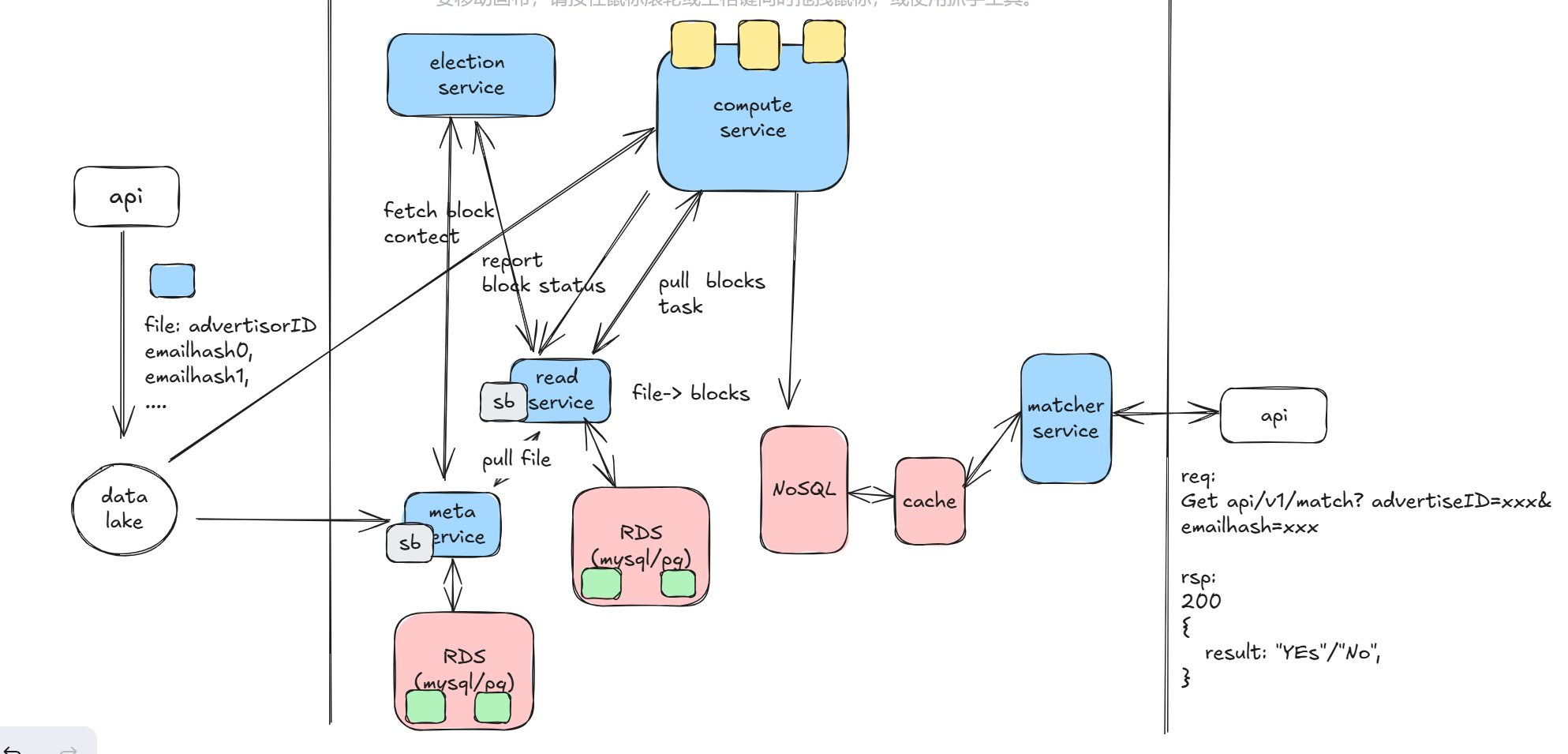
So far, I believe this is a reasonable outcome for the system design. However, I made several mistakes during the process. One reason was my unfamiliarity with the topic, and the other was the way I narrated the system design story.
Tell the story again
At the end, let me tell this story again, dividing it into different layers and sub-questions.
1.Functional Requirements (FR):
The primary function of this system is straightforward: read data from the data lake and support API queries.
2.Non-Functional Requirements (NFR):
The most immediate NFRs include the scale of input data (10k advertisers, 10k~100GB files) and the output API request frequency (10k RPS). It’s crucial to clarify the read semantics provided by the data lake before designing. This includes understanding the interfaces available (e.g., getMeta(filename), getFile(filename, pos, size)) and any potential API frequency or bandwidth limits imposed by the data lake (similar to user resource management capabilities in systems like S3).
3.Further NFRs:
These may include end-to-end latency limits (e.g., within 2 hours), API latency limits (e.g., within 50ms, which may necessitate denying cross-city, cross-national, and cross-continental service access), high availability, and high scalability.
4.System Capacity Estimation:
Based on the previous communication, estimate system capacity, including potential storage options and computing scalability. For instance, 10k files (metadata can be stored in RDS), very large files may need to be divided into blocks for parallel reading and processing. The number of records after processing is 100GB/16B = 6*10^9, which requires NoSQL support.
5.Focus on FR:
At this stage, focus on solving the primary problem: meeting the FR (reading data from the data lake and supporting API queries). It’s best to tackle one problem at a time. For example, cache is a performance optimization issue.
6.High-Level Design + Dataflow:
This part involves a high-level design to explain how data flows through the system, the interfaces between major modules (e.g., RESTful or RPC), and the general form and data schema used for storage.
Here’s the high-level design diagram at this stage. Focus on the major service divisions and intermediate storage. Walk through the entire dataflow to give the interviewer an overall understanding. For interactions between major services, design the API/RPC/database schema (PK/UK design)/SQL for interaction at this stage. This provides a clear overview of a system that meets the basic functions.
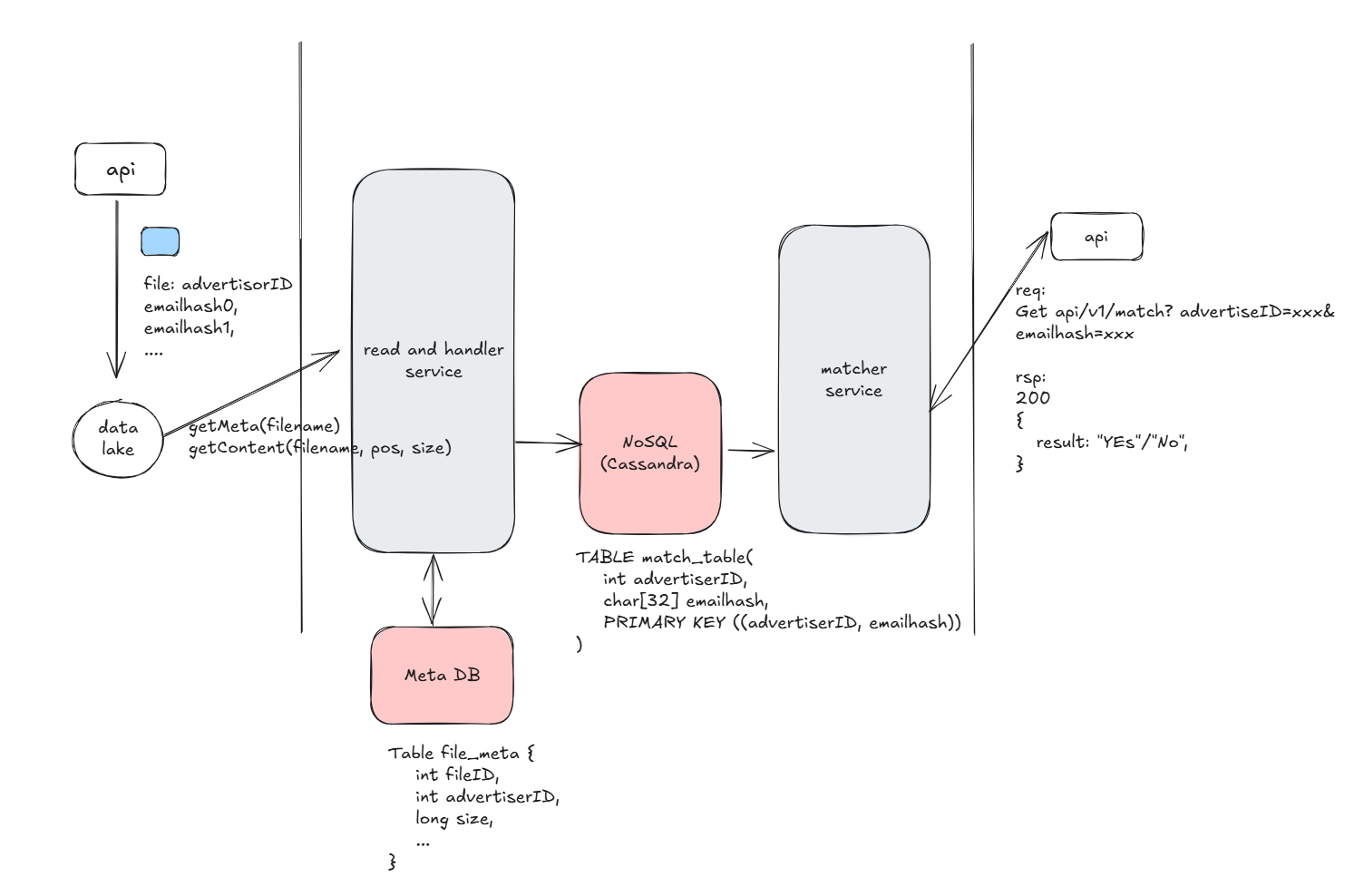
7.The basic functions have not been fully designed yet because the read_and_handler service is too broad. We need to refine it further. Processing files involves two steps: first, obtaining the new file and reading its metadata, and second, reading the file’s content, parsing it, and writing it into NoSQL. Therefore, we will split the original service.
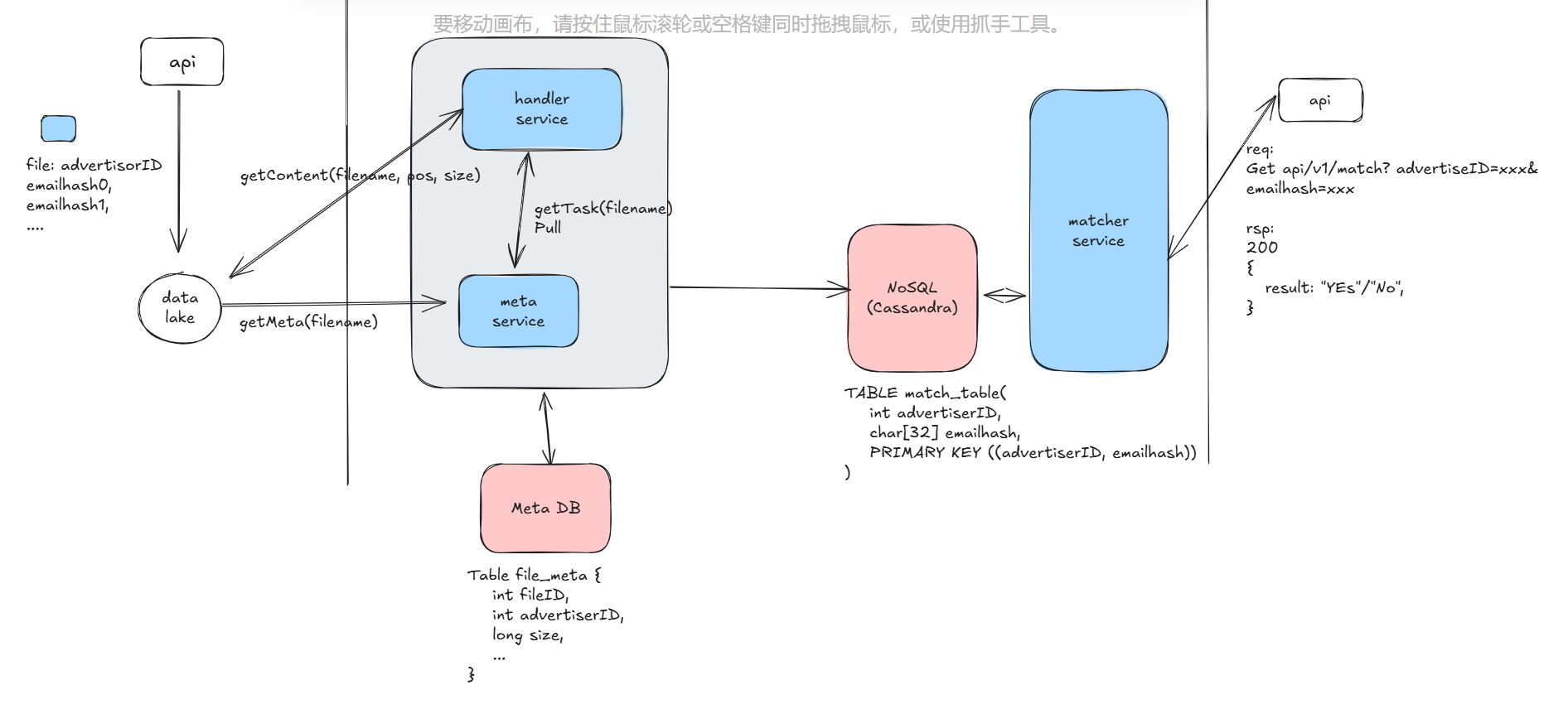
We have separated out a meta service, which is responsible for listening to the data lake for new files and writing them to the database. There is also a handler service that is responsible for reading the file content, parsing it, and storing it in NoSQL.
At this point, we can dive deeper into the design of the meta service and the handler service. Given that a single file may be 100GB or 1TB, we can discuss the performance optimization sub-problem here, which is how to parallelize the reading and processing of large files. There are many issues that can be discussed here, which depend on a lot of context and require many trade-offs. These are all points that can be interacted with the interviewer. For example:
- How to parallelize large file processing?
In this case, you need to split the file into blocks based on the file metadata, for example, into 64MB blocks. Why 64MB? Because it is a moderate size and will not occupy a single compute engine for a long time. If it is too small, it will generate too much file-to-blocks metadata. - How to design a compute service?
Here we need to consider whether we need a stateless compute service or a stateful compute service.- If it is a small team, you can directly design a stateless process/thread pool for parallel processing and transfer failover to the
metaservice. Additionally, it is recommended to use the pull method to ensure that there is no task skew. - If it is a large team, you can reuse compute engines such as Spark/Flink, which can automatically perform task failover and also have task persistence capabilities. The various requirements for the
metaservice are very low and are all transferred to the compute service. The push method can be used.
- If it is a small team, you can directly design a stateless process/thread pool for parallel processing and transfer failover to the
Failover is actually another sub-problem, which we do not need to discuss in detail here. We can consider it when it is discussed to avoid losing focus.
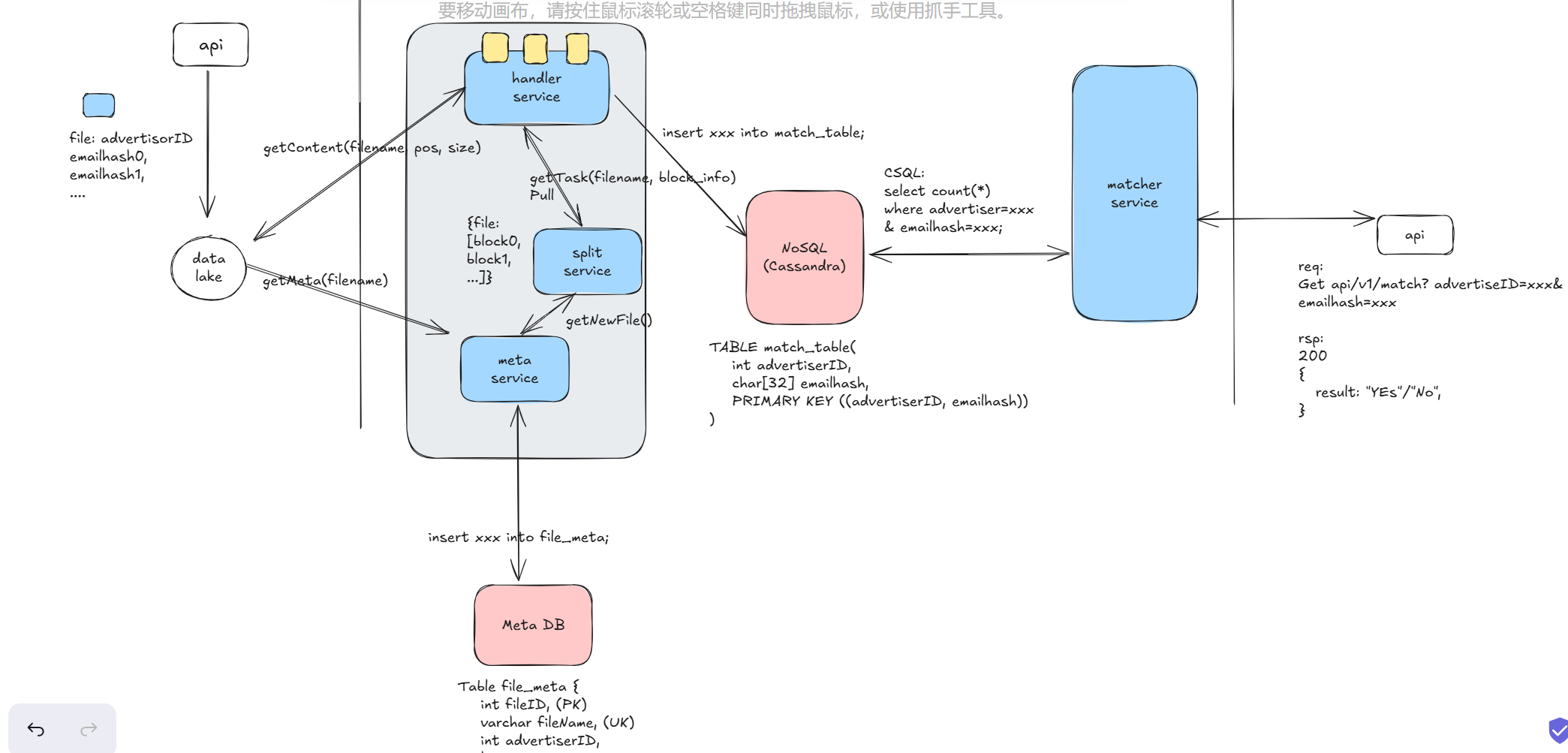
Similarly, for each expanded service, we define their interaction interfaces, which may use push/pull or RESTful/RPC. There is no right or wrong here.
8.Re-examine this design. It meets the basic functions, the end-to-end dataflow is clear, and the interface and data schema designs are reasonable and usable. Next, let’s address how to ensure high availability of the service.
Ensuring high availability is slightly more critical than performance optimization, so we’ll discuss it first. Achieving availability and high availability is a priority before considering speed improvements.
High availability of services includes two main aspects: high availability of computing and high availability of storage.
There are two major types of computing high availability:
- Stateless Compute: This type is only responsible for computing tasks, such as an API gateway that handles authentication. It does not generate any state itself and only queries other states for computing. High availability for stateless compute involves adding a proxy in front, which can be at the IP layer/application layer/transport layer, along with health checks and load balancing.
- Role Stateful Compute: This refers to computing nodes with management responsibilities. These nodes maintain task status and are generally single-point roles in the system. Ensuring high availability for stateful compute typically involves a hot standby and leader election solution.
Storage high availability is also divided into two major types:
- Standalone Storage: For MySQL/PostgreSQL, a master-replica architecture is generally used to ensure high availability, with read nodes performing stale reads.
- Distributed Storage: Systems like Cassandra, MongoDB, ES, TiDB, etc., have built-in high availability capabilities. They offer different read and write semantics, and the architecture choice depends on the scenario’s requirements for consistency, latency, and recency.
Back to our scenario:
- Service High Availability: The matcher service is the simplest, as it is stateless and does not generate any state. We can add a proxy/gateway in front. The meta service has management responsibilities, so we use hot standby and leader election. The split service also has management responsibilities, maintaining block status, so it also requires hot standby and leader election.
- Task High Availability: We need to consider if the file is being processed, if the blocks are being processed, and if the compute service can automatically failover. Here, we assume the compute service is completely stateless, so the split service must maintain block status and resubmit tasks after a timeout. This requires designing the corresponding database schema and timeout mechanism. Another issue is idempotence when a single block task fails. Since files are immutable, the task can be restarted, relying on the database’s primary key/unique key deduplication.
- Storage High Availability: For RDS, a replica architecture can be used for master-slave switching. NoSQL systems inherently have high availability capabilities, so you only need to set the number of data replication copies.
This is our latest architecture diagram after addressing the high availability problem.
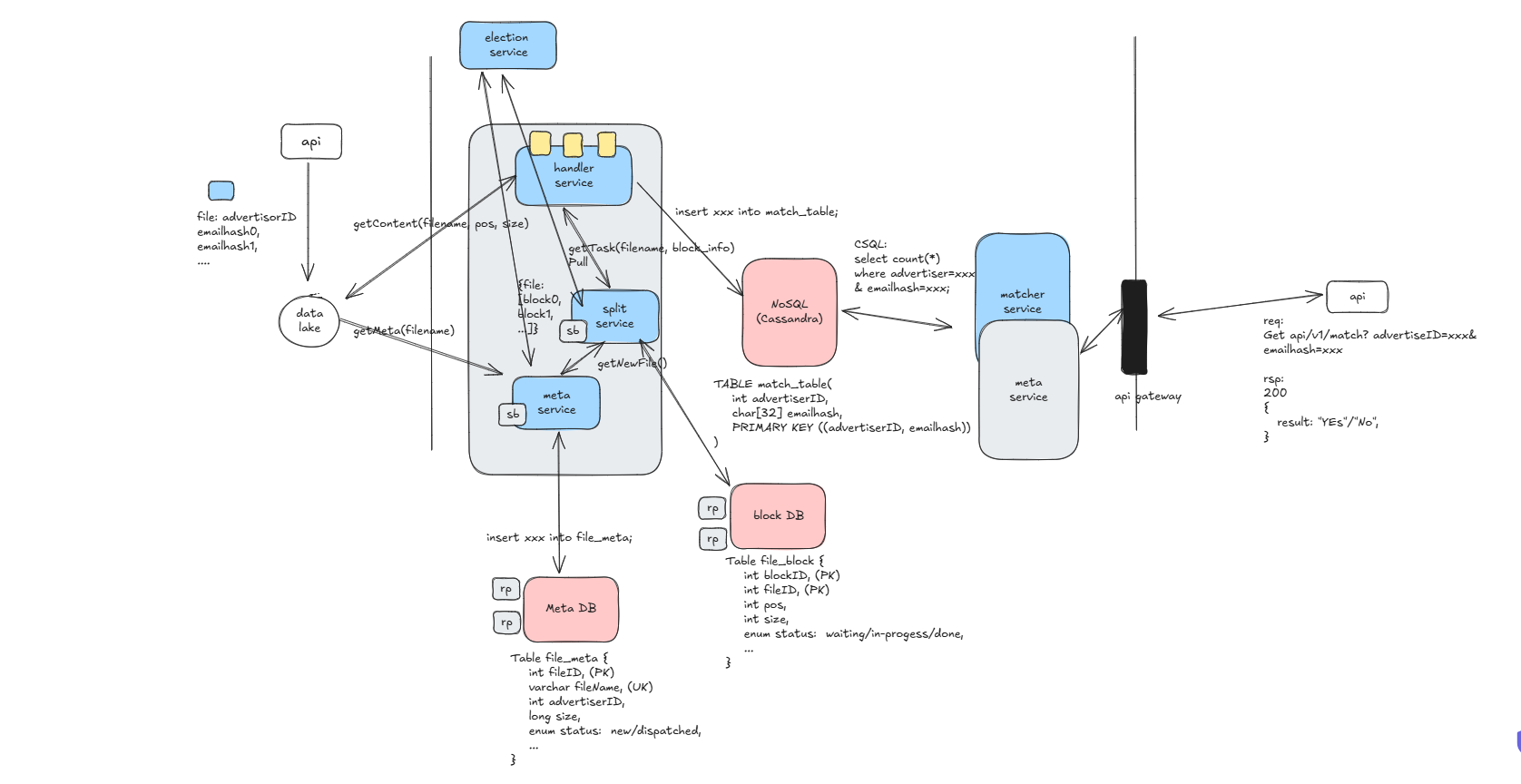
9.Next, let’s address performance and scalability issues. Performance optimization heavily relies on communication. Some performance issues can be resolved by improving program efficiency, while others may require increased costs, such as adding cache or CDN. It’s crucial to confirm through communication whether there’s a demand for these solutions. Another key point is to avoid adding cache mindlessly. Use system metrics, such as API gateway logs or opentrace, to identify bottlenecks causing performance problems in the entire data flow. For scalability, consider designing more stateless compute elements on the critical path to reduce the computational load on single roles during request surges.
10.Moving forward, consider how to decouple different modules of the system, support business-level priorities, meet end-to-end SLAs, implement data tiered storage for cost savings based on the natural 80/20 principle, and ensure service SLAs in geographic service design. These are all valuable discussion topics that can showcase your engineering depth.
In conclusion, a well-designed system should address and solve problems in layers, tackling one issue at a time. This approach allows both parties to focus on a single point, gradually diving deeper from top to bottom, and continuously refining previously designed interfaces and database schemas. This way, you are effectively implementing a system that meets the requirements, with all service interactions and storage schemas thoughtfully designed.
Conclusion
Lastly, remember that system design interviews can sometimes be unequal. When faced with a requirement you’ve never encountered before, it’s natural to overlook some aspects in your design. Interviewers often have preconceived notions, thinking, “Why can’t they think of what I can think of?” They might not consider the problem comprehensively. Regardless, this is an interview. Focus on improving your expression and communication skills. Don’t expect to design a perfect system in one hour.
Oh, it’s not over yet. Another major pitfall in system design interviews is being asked to introduce the architecture diagram of your past projects. I used to jump straight into drawing the architecture diagram, making it look very polished, but this approach often led me into a trap.
If you understand what I mentioned earlier, you should realize that the goal of system design interviews is to evaluate how you address a practical need through effective communication.
So, when introducing your project,
- You must first explain clearly why you want to do this, what problem this thing solves, and define one or more specific problems.
- Clearly define your inputs and outputs, and what the end-to-end result is.
- Discuss some NFRs of your project, such as the amount of tasks supported, latency requirements, high availability requirements, high scalability requirements, etc.
- Describe the different services and roles in your system in the form of system design, and explain why you designed and chose them this way. Describe your choice of computing storage, such as metadata storage.
- In the above process, we need to draw the dataflow and how the dataflow flows.
- After meeting the basic functions, introduce how your system ensures high availability of services, tasks, and storage, how to optimize performance, and how to handle some abnormal system problems (GC stop).
- At this point you will basically get a system architecture diagram, based on which you can add some additional extensions, such as add-ons.
In this process, you are basically explaining to others why you got such a design, what information you got from which people, and which made you decide to make such a tradeoff. This part is selling your problem solving ability, communication ability and engineering ability.