
在上一个博客中,我们介绍了进程管理相关的内核概念。进程管理是从内核角度看待问题,因为对于内核而言,所有的代码和数据,包括用户代码和数据,都属于动态内核的一部分,因为他们都维护在内核提供的进程描述符 task struct 中。
但是这部分视角是用户感知不到的,从编程人员的角度看,编程的时候内核其实完全不存在,或者说只存在一些编程规范而已,比如函数逻辑要从 main 开始,要区分堆栈,要区分进程和线程。所以这篇博客我们要再切换下视角, 观察下用户视角和内核视角下,用户代码和内核代码是如何切换运行。
用户态和内核态
这两个概念对于做后台开发的同学而言很熟悉,最常听见的说法是:要减少用户态到内核态的切换,避免不必要的开销。要说清楚这两个概念,我们也从几个问题开始:
- 用户态和内核态是什么?
- 用户态和内核态的存在形式是什么?
- 用户态、内核态和内核的关系是什么?
- 用户态切换内核态,内核态切换用户态都有哪些时机?需要哪些开销?
对于这几个问题,一个简单的回答是这样的:
- 用户态是 CPU 在执行用户编写的逻辑和数据时的状态;内核态是 CPU 在执行内核代码和访问内核数据时的状态。 内核态可以访问一些硬件相关的操作,权限更高。
- 用户态的存在形式是用户编写的逻辑和关联的数据;内核态的存在形式是内核代码和内核关联数据。
- 用户态和内核关系不大,内核态时执行的是内核的代码和关联数据。
- 用户在访问硬件资源时,比如读写文件,获取网络数据包等,依赖内核提供的系统调用完成从用户态到内核态的切换。中断也会导致用户态到内核态的切换。当内核态执行完成之后,返回用户态。
这个回答符合对于用户态和内核态的定义,但是我们需要知道为什么要这些概念,如何实现这些概念,以及用户态和内核态这两个概念的关系和交互。
数据隔离和操作保护
我们把视角再往回拨一下。在内存篇中,我们知道了进程的分页机制,本质上除了为用户隔离物理内存的相关概念之外,还可以提高物理内存利用率。我们不需要提前将具体某块大小的物理内存区间分配给进程 A。每个进程都是以一样的进程页表机制获取物理内存,只有在访问线性地址页时发现没有分配物理内存页的情况下,才会动态分配物理内存。
这里的关键问题是,查找页表和分配物理内存这个行为本身是高危的,要防止贪婪和恶意的用户编写代码操作这个行为,这样会和内核产生冲突,同时会影响其他进程实体的数据安全。
相同的原理可以对应到操作文件和网络设备,网络数据包是按时间顺序到达的,没有内核合理的分发,其他进程就可能获取到本进程的数据包,导致本进程数据包不完整。
所以这里就出现了需求,对于高危操作,所有进程都要委托给内核操作,并且内核代码和关联数据都要设置高权限,即使用户用汇编自己构造合法的线性地址,也没法访问对应的内核代码和操作内核数据。
注意:
这里有个表述上关联的小细节,在整个进程线性地址中,既有用户自己的代码区/数据区/堆区/栈区等等,还有内核映射的每个进程高线性地址区间[3G, 4),所以用户是可以用汇编语言自己构造 访问位于内核所在的高线性区间的。虽然 CPU 此时权限不足无法访问内核线性区间,但是这样理解可以加深我们对于用户态和内核态在权限管理上的区别.
这就是用户态和内核态概念出现的原因。
Linux 内核是为多用户多进程服务的,内核除了要维护分时复用和进程线性空间这些抽象概念之外,还要考虑到独立实体之间的数据和自身核心操作的安全问题。
除了给不同的线性区赋予权限之外,为了实现内核态,我们还需要知道一个问题:
- 怎么防止用户构造指令切换到高权限,从而访问高权限的数据?
- 在一切都是机器码的前提下,既然系统调用可以切换到内核,为什么用户代码就不可以?
硬件相关的执行权限控制
要回答上面的问题,就涉及到硬件相关的权限设置。在内存分段的时候我们提及过段寄存器的概念,其中的 cs 代码段寄存器中的代码段选择符就承载了 CPU 当前执行特权级。具体的,代码段选择符的低 2 bits(CPL/RPL) 就代表当前 CPU 的特权级,
0 为内核态,3 为用户态。

假设用户想要自己提高 CPU 权限,直接用汇编装载 cs 寄存器内容 asm(“movl $Kernel_Code %cs”), 这样 CPU 执行到这句时会给进程产生一个 General Protection Fault 的异常,因为 CPU 发现此时的用户态权限无法操作控制寄存器 cs。
除非通过中断,异常或者内核提供的系统调用这些硬件系统和内核提供的特殊入口方式,用户是没法通过自己构造线性地址或者操作一些控制寄存器的方式访问内核的代码和数据。
NOTE:
如果内核有 bug 导致执行了某些内核逻辑之后一些控制寄存器没有正确设置就切换回用户态,用户也可能有机会能获取到权限。
这里简单提及下中断中,硬件是如何参与用户态到内核态切换的。
- 当 CPU 在执行完一条指令后,CPU 会检查在指令执行期间是否有中断发生。
- 如果发现有,CPU 硬件电路会自动保存 cs 和 eip 等寄存器值到内核栈(后面解释这个概念),然后再跳转到内核的对应中断处理程序。注意,这里从检测到中断信号,一直跳转中断处理程序都是硬件做的。
用户态切换内核态时机
在三种场景下,会导致用户态切换内核态:
- 中断
- 异常
- 系统调用
- 中断是 Intel 定义的随机产生的硬件电信号导致的一类异步事件,比如敲击键盘、网络数据包到达和时钟中断等。
一般情况下,相对于执行流,这些硬件电信号是稀疏的,但是对实时性要求会比一般程序要高,内核需要尽快处理这些中断电信号。 - 异常是 Intel 定义的同步中断,也会打断当前 CPU 的执行流。在产生时机上它一般是由于用户编程异常导致,比如执行指令遇到了”除 0”,”溢出” 和上面说的由于权限不足导致的 “General Protection Fault”。
- 系统调用是内核提供给用户访问硬件资源的唯一方式。通过内核预定义的各种文件/网络系统调用,用户程序完成用户态到内核态的切换,并向内核注册需要对硬件操作的信息。
同时也允许内核在资源未准备好时做些其他事情,比如切换到其他进程执行,等硬件资源准备好之后再切换回该进程,继续执行。
这 3 个场景,有不同的分类方式:
- 中断是异步的,中断发生的时机和当时正在运行的进程都是随机的;
而异常和系统调用都是同步的,异常由用户程序的异常执行触发,系统调用由用户程序主动调用。 - 中断处理例程、异常处理例程和用户程序没有关系,是其他独立的执行逻辑;
系统调用虽然是内核程序的一部分,但是可以认为是用户程序的部分延续,在逻辑上继续访问硬件相关资源。
中断
中断触发和识别
中断是硬件电信号触发的异步事件,在硬件上依赖 IRQ 线和 8259A 中断控制器,电子信息专业的同学在上微机原理课的时候会接触到这些硬件单元。每个能够发出中断请求的硬件会通过 IRQ 线连接到中断控制器中,每次触发电信号时中断控制器就把引脚
序号转换成中断向量,通过不同的中断向量区分不同的中断类型,比如是键盘触发还是网卡触发。
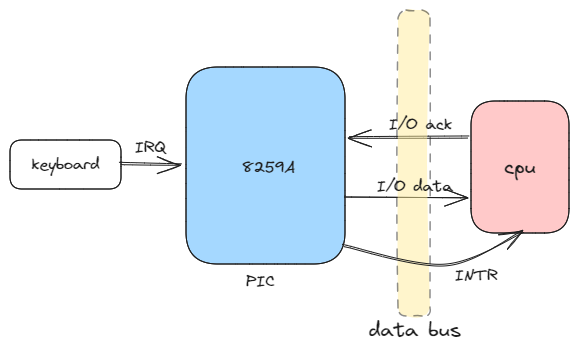
source
中断处理程序
有对应的硬件机制区分不同的中断类型之后,自然需要不同的中断处理程序,这些中断处理程序是内核中的一段逻辑,注意不是进程或者线程。
对于操作系统抽象了解不深的同学会难以想象用户进程和内核逻辑、中断处理程序之间的关系,没法在脑海中想象当发生中断 或者异常或者系统调用时,执行流到底是怎么切换的。
一种比较好的方式是,想象只有一个 CPU,那么在一个时间点就只能做一件事情。不管是内核,还是进程,还是中断处理程序本质上都是一段要顺序执行的代码逻辑。然后 CPU 上有个电信号能够打断 CPU 当前的执行流,将旧的 context 保存在特定的地方等待恢复。不管怎么打断 又选择其中的哪个执行,最终也就是在内核逻辑,进程逻辑或者中断处理逻辑中跳来跳去而已。
核心还是能够随时打断并恢复执行流的能力。
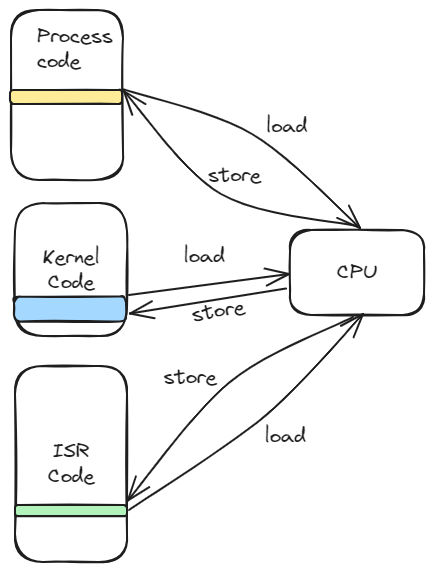
source
讲回中断处理程序,既然他是内核中预先写好的一段处理逻辑,那就需要维护元信息,就是这些处理逻辑放在内核的什么地方,这就是中断描述符表。中断描述符表是存储中断描述符的数组,中断向量就是数组的序号。该表在内核初始化的时候直接初始化赋值,表 的线性地址存放在 idtr 寄存器中。 每个中断描述符有 8 字节,其中中断门描述符 中比较重要的字段是段选择符、中断处理程序在段内的偏移 Offset 和 DPL(Descriptor privilege Level)。
- 段选择符:指明中断处理程序属于哪个段。因为都属于内核代码,所以都是 $Kernel_Code。该字段值会被放入 cs 寄存器中。
- Offset:之前说过 linux 不使用段的概念,所以段 base 都是 0,这个逻辑地址和线性地址值也就一样。因为中断只有中断向量传递给内核,所以具体要跳转的处理程序开头地址就是这个字段的值。该字段值会被放在 eip 中。
- DPL: 用于编程异常时检查权限。正常硬件中断检查的是中断描述符中对应段选择符对应的 GDT 中段描述符的 DPL,不是这里的 DPL。
跳转中断处理程序
简单描述中断是如何被处理的:
- 硬件触发一个中断。
- 在执行完一个指令之后,CPU 中硬件电路检查是否发生。发现有,CPU 硬件电路读取引脚上传递过来的中断向量,查 IDT 中断向量表和 GDT 段描述符表。对比当前 cs 寄存器中的 CPU 特权 CPL 和段描述符中的代码特权级 DPL,允许在用户态 或者内核态时处理中断,但是不允许内核调用系统调用这种奇怪的场景。
- 权限检查通过后,CPU 硬件单元切换到中断内核栈(下个小节介绍),把旧的 ss、esp、cs 和 eip 这些寄存器的值压入中断内核栈。注意,这里是 CPU 内部的硬件电路保存了部分的硬件上下文,后面内核还要保留部分硬件上下文才能 完整恢复执行流。
- 将对应中断描述符中的段选择符装载到 cs 寄存器中,将中断描述符中的 Offset 装载到 eip 寄存器中。从这里开始,CPU 开始执行内核中对应的中断处理程序。
中断内核栈和硬件上下文
中断内核栈是内核中的一块内存,和进程用户态栈区在概念上不同。它不是线性地址空间中线性区的概念,而是一块内存,它更接近于进程内核栈(在系统调用小节中介绍),权限是内核态。之所以不直接用进程内核栈主要有两个原因:
- 逻辑上,中断和中断处理程序并不属于任何进程,它是一个独立机制的单元,可以随机分配给不同的 CPU 处理,也无法预知执行时对应哪个进程。
- 避免中断处理程序错误操作进程内核栈,比如错误将进程内核栈的内容 pop 掉或者 push 进不需要的内容。
中断内核栈所用的内存在内存初始化时初始化,是个每 CPU 内存块。拓展阅读: https://www.kernel.org/doc/Documentation/x86/kernel-stacks
中断发生时,可能存在 3 种方式的栈切换:
- 用户态栈切换中断内核栈
- 用户进程内核栈切换中断内核栈(系统调用内核路径->中断)
- 中断内核栈到中断内核栈(中断->中断,中断嵌套)
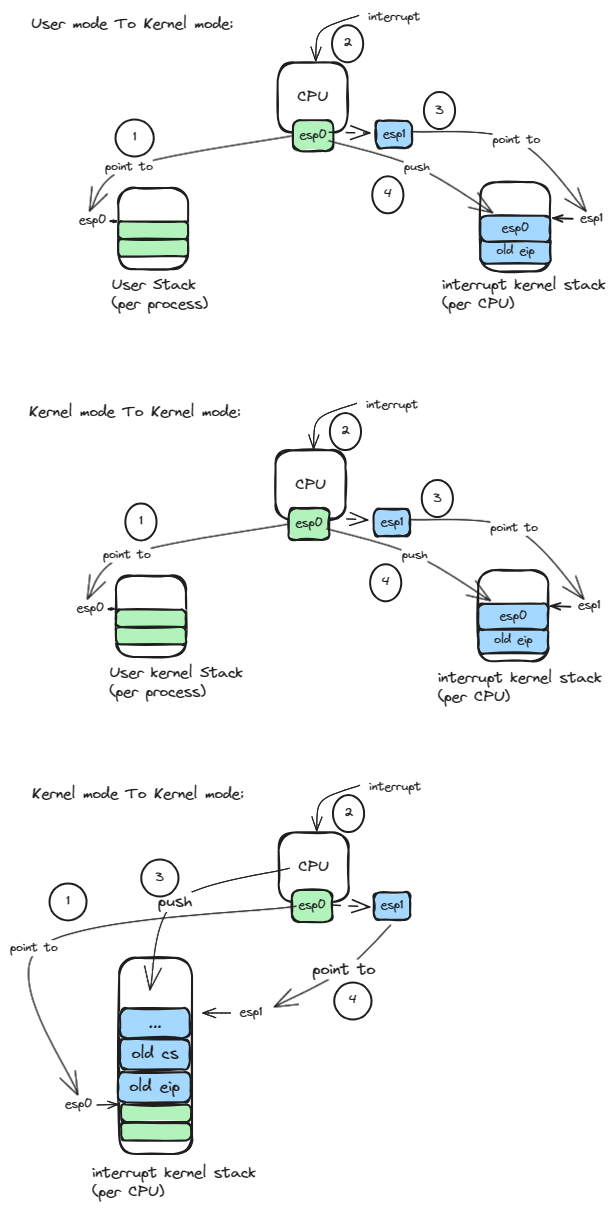
TSS 任务状态段
中断内核栈的寻址和任务状态段 TSS(Task State Segment)有关,这是 intel 为任务切换设计的硬件关联段。
在早期设计中,intel 设想在任务切换时将所有的硬件上下文都保存在每个进程自己的 TSS 中,但是 linux 为了兼容不同硬件并没有完全使用这个机制,而是选择软件保存上下文,只是有限使用 TSS 段来保存 IO 权限位信息和中断内核栈的相关信息。
具体的,内核在初始化时初始化了 init_tss 数组,为每个 CPU 初始化预留了一个 tss 结构体,init_tss 数组在内存中的地址保留在 tr 寄存器中。
这样当从用户态或者内核态切换到中断处理程序时,如果检查到当前栈不是中断内核栈时,CPU 硬件单元就可以访问 tr 寄存器找到对应 CPU 的 tss 内存位置,并加载 tss 中的 ss 和 esp 寄存器值内容到对应的寄存器中,从而实现切换到中断内核栈。之后,将旧的 ss,esp,eip,cs 和 eflag 寄存器的值存储在中断内核栈中,以便中断处理程序运行完后返回原来的执行流。
注意这里使用的 tss 机制是 x86 架构的,不同的架构可能使用的机制不同,有兴趣深入的同学可以参考。
TSS wiki
StackoverFlow tss
当不需要切换中断内核栈时(中断嵌套),就不需要保存旧的 ss 和 esp 寄存器内容到内核栈中。
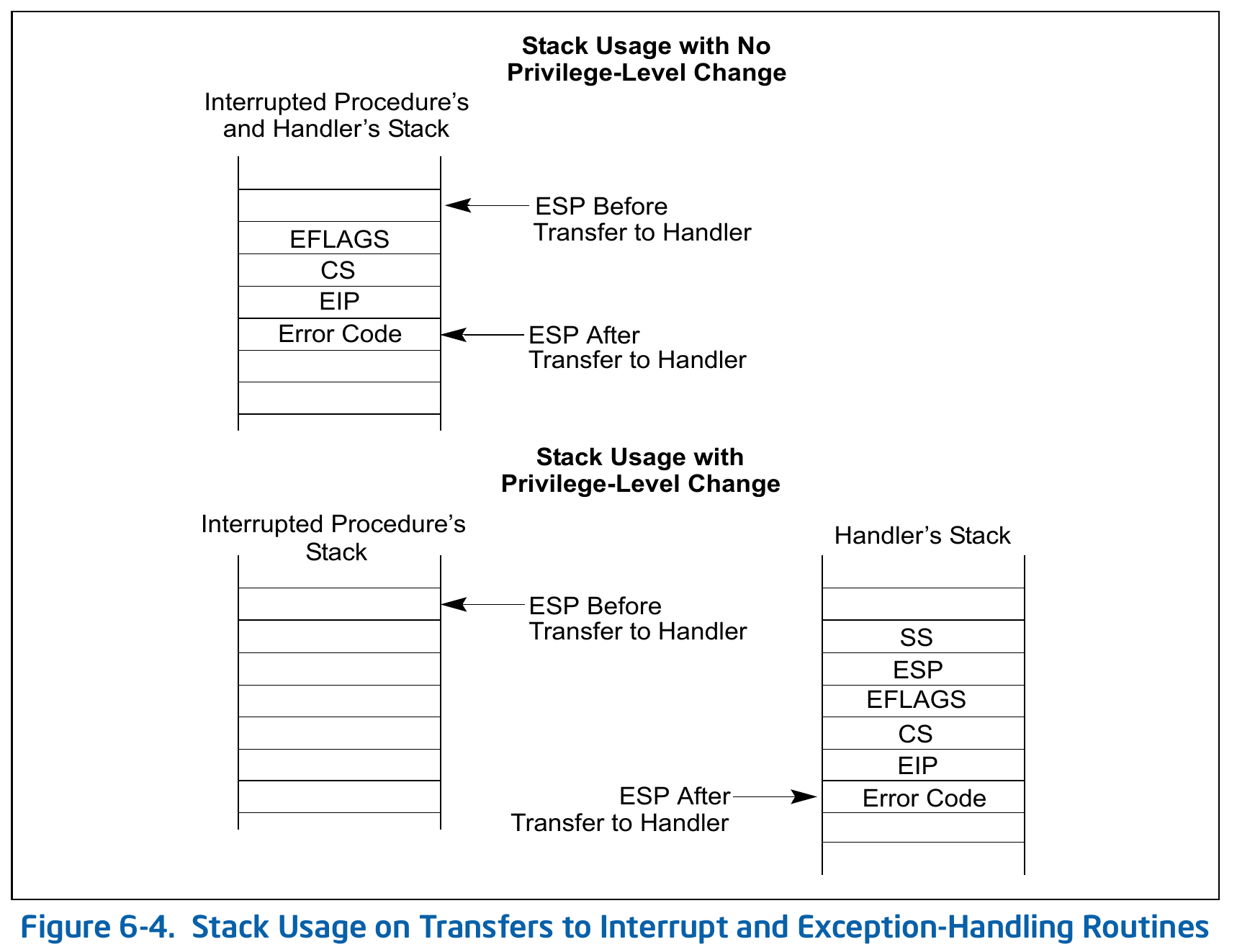
这里其实只保留了部分的硬件上下文,比如通用寄存器等还没有被保存,那部分的寄存器是在进入中断处理程序之前保存的,那是软件机制保存的。在所有的中断处理程序之前,都会执行 common_interrupt 的逻辑:
common_interrupt:
SAVE_ALL
movl %esp, %eax
call do_IRQ
jmp ret_from_intr
macro SAVE_ALL:
cld
push %es
push %ds
pushl %eax
pushl %ebp
pushl %edi
pushl %esi
pushl %edx
pushl %ecx
pushl %ebx
movl $ _ _USER_DS,%edx
movl %edx,%ds
movl %edx,%es
到这里为止我们保存了剩余部分旧硬件上下文。
我之前对这里有个疑问,就是没有看到浮点寄存器相关的值被保存,后来想想内核只要不是做进程切换,就可以不保存这些寄存器的值,因为内核用不上也不会改变这些寄存器的值。
常见的硬件上下文基本分成以下6类:
- 指令寄存器:EIP,RIP,IP 等
- 标志寄存器:EFLAGS,FLAGS,RFLAGS 等
- 段寄存器:CS,DS,ES,FS,GS,SS 等
- 通用寄存器:EAX,EBX,AX,BX 等
- 栈指针寄存器:ESP,EBP,SP 等
- 基指寄存器:BX,SI,DI 等
中断嵌套
中断是一类稀疏随机的异步事件,所以内核需要尽快响应处理中断,所以内核在一般情况下都允许中断嵌套执行,也就是在一个中断处理程序中如果发生了其他类型的中断,则中断处理程序的执行流也会被切换到另一个中断处理程序。
注意这里的用词,我们说允许其他类型的中断,因为同类型的中断如果允许嵌套就会出现数据竞争的情况,所以同类型的中断在进入中断处理程序时就被屏蔽掉了,但是这些电信号不会消失,只是 pending 而已。等该类型的中断处理程序执行完之后,打开中断则可以再次触发 pending 的中断。
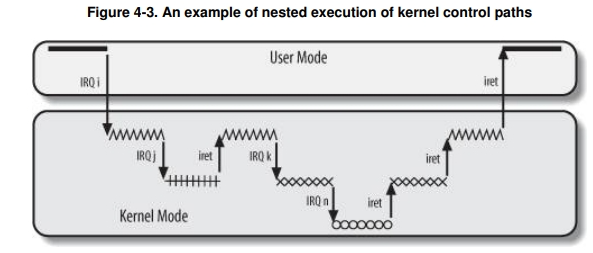
对于允许中断嵌套的操作,书中给出的答案是:
- 提高中断控制器和设备控制器的吞吐。意思是说,对于不同类型的中断,允许嵌套后,CPU 能及时读取中断引脚的中断向量,直接给 PIC 一个应答信号,不用等待 CPU 把上一个中断处理程序都运行完后再给下一个中断信号进行应答。
核心就是,把电信号应答和逻辑处理分离开来,提高中断硬件设备的吞吐。 - 实现一种没有中断优先级的中断模型。内核不用实现复杂的中断优先级控制,因为不同类型的中断没有区别,可以互相嵌套。
对于中断嵌套执行,我还是有 2 点疑问:
- 中断嵌套时会屏蔽同种中断,所以其实这个增加吞吐其实是不同中断类型的吞吐。只是能触发中断的设备类型不多,看起来没有想象中那样有用,毕竟同种中断因为上一个中断服务程序没有结束还在阻塞着。
- 中断嵌套之后,会导致原来的中断处理程序耗时增加,因为有硬件上下文切换。中断处理本身已经把一些耗时的逻辑分离成了异步执行的 tasklet, 所以中断处理程序本身应该是比较精简的,如果允许嵌套则可能会导致增加耗时,对于吞吐的影响有多大呢?
还有一点是中断允许嵌套执行之后,需要保证中断处理逻辑永不阻塞,也就是不能发生 kernel preemption 导致 current 进程切换。
我对这个理解其实不深,直觉上允许中断执行期间进程抢占会导致中断处理时间不可控,正常的时钟中断间隔大概是 1ms 左右。其中应该还有一些死锁的问题,没有太想明白。
这里有个概念上的细节也要区分开,中断嵌套和内核抢占 kernel preemption 是两个概念,后者是用户进程优先级导致的执行流切换,不是硬件中断导致的执行流切换。
软中断 softirq 和 tasklet
软中断和 tasklet 是 linux 中断机制的提高性能的一个设计,将中断处理中紧急的部分和非紧急的部分分离开来,非紧急部分注册到内核中延迟处理。tasklet 是软中断的一种类型,在实现约束上,内核要求软中断是可重入的,不同 CPU 能同时运行同一种软中断,所以大部分实现需要通过加锁的形式 保护关键资源。而 tasklet 则可以是不可重入的,因为内核会调度相同的 tasklet 串行执行。
Linux 2.6 定义了 6 种类型的软中断,低下标表示高优先级。同种类型软中断任务通过链表的形式维护在软中断数组的对应位置,当软中断在一些场景下激活执行时,会持续处理有限个数的挂起软中断,其他的会唤醒内核线程 ksoftirqd 继续处理。


内核线程是所属于内核的具备进程上下文的特殊进程,它的 特点是不会访问进程用户线性地址空间[0, 3G), 所以内核进程在执行的时候会借用上一个用户进程的进程页表,这个到进程切换时我们再详细描述。该内核线程大致的工作如下:
for(;;) {
set_current_state(TASK_INTERRUPTIBLE );
schedule( );
/* now in TASK_RUNNING state */
while (local_softirq_pending( )) {
preempt_disable();
do_softirq( );
preempt_enable();
cond_resched( );
}
}
异常
与中断不同,异常是和特定进程绑定的,比如编程错误、调试程序和缺页异常等,也就意味着异常可以延迟处理,因为可以通过给进程结构体某些标识比如信号的方式,让进程稍后得到 CPU 时间的时候再处理。其中还要提及的一点是,大部分异常发生在用户态,而缺页异常发生在内核态。
异常触发不同于中断的电信号,而是属于 CPU 架构和机制的一部分,定义在 CPU 的指令集中,但还是通过内核统一入口,就是中断描述符表进行异常处理逻辑的维护。
当异常发生时,CPU 硬件会自动切换到异常内核栈,流程类似于切换中断内核栈,也可能复用的中断内核栈或者使用其他 CPU 架构相关的机制。硬件自动保存了部分硬件上下文,内核代码手动保存了部分硬件上下文。
系统调用
库函数和系统调用
在刚接触编程的时候,由于对系统设计不熟悉,总是搞不清楚系统库和系统调用的关系。
Linux 库函数是一类 API 的集合,比如常见的 libc 和 libc++,大部分 API 符合 POSIX 标准。库函数中可以封装系统调用,也可以不使用系统调用。本质上库函数是想提供给用户一类便捷可移植的规范定义 API 接口,比如 API 的名字、传参和返回值等,屏蔽掉不同操作系统提供的相同功能但不同定义的系统调用,是个中间层。
举个例子,平时在分配堆内存时使用的 new 或者 malloc 操作的是库函数,原因在于频繁调用系统调用从堆区申请小内存要频繁切换硬件上下文,影响程序效率。所以系统库会一次申请一大块内存,然后根据某种小内存划分算法维护小内存块,这个类似于 slab system,只有在上一次申请的内存完全消耗完之后才会再调用 brk 系统调用再申请 一次大块堆内存。 这个例子中库函数封装了用户态对大块堆内存的维护逻辑,封装了效率操作,也隐藏了对应的 brk 系统调用。
触发方式
系统调用的触发方式通过 INT 0x80 或者 sysenter 指令,前者类似于触发一个硬件中断信号,不过是 CPU 提供的软件中断机制,中断向量是 128,对应在中断描述符表中是个 trap gate 描述符。
系统调用服务例程
所有的系统调用通过 INT 0x80 进入内核态之后,就要有机制识别不同的系统调用,比如读写文件或者读写网卡的系统调用。不同的系统调用码是通过 eax 寄存器传递的。我们在编程中没有用过是因为我们基本使用的都是对应的库函数,库函数封装了这些调用硬件约定相关的操作,我们只需要考虑传递什么样的参数给系统调用,然后获取什么样的返回值就行。
同样,有了不同类型系统调用的识别机制之外,就要能定位到不同系统调用处理例程的入口,这个存储在 sys_call_table 表中,在内核初始化的时候初始化。sys_call_table 中每个表项占据 4 字节,存储的是对应系统调用服务例程的起始地址。
系统调用流程
简单描述系统调用流程:
- 进程切换到当前进程并处于用户态,在进程切换过程中内核将当前进程的进程内核栈(下一小节解释)地址写入当前 CPU 的 TSS 段中。
- 用户代码调用库函数 API,库函数处理了一些系统调用传参和系统调用号传递的逻辑,将它们按照硬件约定放在对应的寄存器中。
- 库函数内部调用 INT 0x80 或者 system call。
- CPU 硬件开始执行和中断类似的查表流程,主要是中断描述符表和全局描述符表,检查权限。
- CPU 硬件检查到当前的用户态栈权限不符合要求,需要切换到高权限的进程内核栈,所以开始读 CPU 对应的 TSS 段中的栈寄存器值 SS 和 ESP,切换到内核栈。
- CPU 硬件切换进程内核栈后,将旧 SS、esp、eflag、cs 和 eip 等值保存在进程内核栈中。
- CPU 硬件将 $kernel_code 和中断描述符中的 offset 地址装载到 cs 和 eip 寄存器中, 跳转执行 system_call 函数。
- 内核中的 system_call 函数开始接管系统调用的执行,首先保存一些硬件上下文,然后根据系统调用号再次跳转到对应的系统调用处理例程。
system_call: pushl %eax SAVE_ALL movl $0xffffe000, %ebx /* or 0xfffff000 for 4-KB stacks */ andl %esp, %ebx ... call *sys_call_table(0, %eax, 4)
进程内核栈
这里有个很核心的概念,就是进程内核栈。和用户栈类似,进程内核栈是专门用来给内核函数做函数调用和传参使用的一块内存。需要注意的一点是,书中使用的是内核栈,而不是进程内核栈,但是仔细关注书中其他模块使用的内核栈,就会发现其实存在不同类型的内核栈,比如中断使用的内核栈就不是进程专属的内核栈。所以这里加了一个限定词,以便区分。
系统调用是用户进程的一个主动行为,和进程绑定,所以每个进程有个专属的进程内核栈会有更加清晰的所属关系。
有个有意思的细节,就是内核栈是和 thread_info 放在一起的。thread_info 中存在的是执行流信息,也就是在进程切换时的硬件上下文。我们前面说线程是最小的执行单元,它的另外一层意思是指 thread_info 中存储了执行流的大部分硬件上下文,恢复执行流时需要用到 thread_info 中的寄存器信息。还有一部分
硬件上下文在内核栈中,是中断时硬件电路自动保存的。
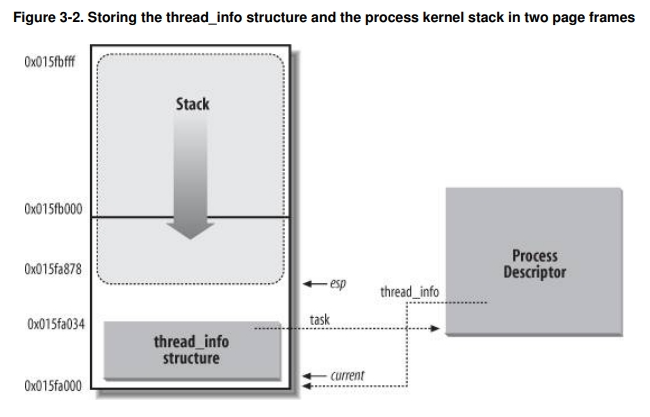
之所以把内核栈和 thread_info 放在一起,是因为内核需要频繁获取当前在 CPU 上执行的进程描述符 task struct。一开始在 linux 内核中是用的全局静态变量保存的,到了多 CPU 的架构下就需要使用 CPU 数组的形式 区分不同的 CPU current task。现在内核直接用 esp 寄存器值计算出 current, 因为 thread_info 放在了一个 8k 连续地址空间的最低处,所以直接屏蔽掉低 13 bit 即可获取当前内核栈对应的 thread_info, 而 thread_info 中存储了所属 task struct 的反向引用(指针),所以就可以找到 current task。
union thread_union {
struct thread_info thread_info;
unsigned long stack[2048]; // 8k
}
struct thread_info {
struct task_struct* task;
...
}
func current_thread_info {
movl $0xffffe000, %ecx
andl %esp, %ecx // mask the lowest 13 bit
movl %ecx, p
}
macro current {
movl $0xffffe000, %ecx
andl %esp, %ecx
movl (%ecx), p // pointer to task struct is at the offset 0
}
总结
用户态切换内核态是一种数据和操作保护的抽象,同时也是系统提供分时复用机制的基础(时钟中断)。在 linux 系统中,主要有 3 种方式会导致用户态切换到内核态,我们也从核心概念上分别描述了它们分别是什么样的机制和流程。
作为总结,我们再次回答文章开头提出的问题:
- 用户态和内核态是操作系统提供的权限管控概念,依赖硬件机制控制不同的 CPU 执行权限,从而实现不同权限数据和代码的保护。
- 用户态和内核态存在形式是,硬件机制触发的 cs 寄存器的改变。cs 寄存器中的 CPL 字段决定了 CPU 权限,0是内核态,3是用户态。
- 用户态和内核态是抽象的权限概念,内核有静态和动态的实体,关系上而言,内核态代码属于静态内核,用户态代码属于动态内核。
- 中断、异常和系统调用都会导致用户态切换到内核态,具体开销包括切换内核栈、保存硬件上下文和执行内核服务例程的一系列操作。