
进程调度是内核运行调度的核心章节,主要内容涉及 2 个方面:
- 进程切换,这是分时复用抽象的核心机制,涉及进程切换时机和切换机制。
- 进程优先级调度,动态调整进程优先级,满足进程公平调度需求,同时满足业务对不同形态进程的调度需求。
进程优先级调度
在设计任务调度问题时,有几个通用的问题:
- 任务是否有不同的重要程度?是否需要设置不同的优先级?
- 任务是否存在不同的类型?不同类型之间的优先级是否可以互相比较?
- 任务调度使用什么算法?是否能保证不同进程能合理获取 CPU 时间,不至于在一段长时间间隔内无法运行?
进程运行时类型
linux 内核根据任务对资源的使用方式将进程分成 3 类:
- 交互式进程:频繁等待外部输入,比如等待鼠标和键盘的输入,要求有响应外部事件的延迟足够短,避免用户感受到操作迟钝。
- 批处理进程:不需要等待外部输入,后台运行,计算型进程,比如编译程序和科学计算程序。
- 实时进程:业务逻辑上对实时要求很强,需要短而稳定的响应时间,比如音视频类应用程序。
交互进程和批处理进程在 linux 中被归类到了普通进程中,需要通过对程序对 I/O 或者 CPU 时间片使用的统计信息进行归类。实时进程由用户指定。
调度算法
调度算法在大体上需要满足以下几个目标:
- 进程响应时间尽可能短,尤其对于交互式进程。
- 后台作业吞吐量尽可能高,意味着批处理进程获取尽可能长的 CPU 时间片,一次性做尽可能多的计算。
- 高优先级进程和低优先级进程尽可能调和,高优先级进程优先运行,但是低优先级进程不能出现饥饿现象,在一个长的时间段内无法获得任何运行机会。
基于以上目标,调度算法主要有以下几个特点:
- 区分普通进程和实时进程的调度算法。
- 区分静态优先级和动态优先级。
- 静态优先级决定进程的最长运行时间片,同时作为动态优先级的初始条件。
- 动态优先级根据进程休眠时间调整,大致逻辑是当进程长时间无法获取 CPU 时间时,就增大动态优先级。否则占用 CPU 时间过长就降低动态优先级。
- 内核维护 140 个优先级链表,进程根据动态优先级被转移到不同的链表中。
普通进程调度
普通进程的静态优先级从 100(最高) 到 139(最低),子进程总是继承父进程的静态优先级,但是内核提供了 nice 和 setpriority 运行进程设置自己的静态优先级。
静态优先级决定进程基本时间片(quantum),如下:
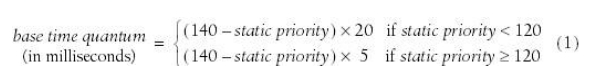

可以看出静态优先级越高,quantum 越长。举个例子,假设系统只有 1ms 间隔的时钟中断,当一个进程 A 的 quantum 是 50ms 时, 每次时钟中断处理例程在检查进程动态优先级时都发现进程 A 的优先级是最高的,那进程 A 可以连续运行 50 个 1ms 间隔。
进程 nice 值是静态优先级和 120 的差值,表达的是一个意思。
动态优先级的取值范围也是 [100, 139),由一个经验公式计算得出:
dynamic priority=max(100, min(static priority-bonus+5, 139))
static priority 作为 dynamic priority 的 baseline, bonus 则是根据进程平均睡眠时间对进程的奖赏。
进程平均睡眠时间越长,bonus 越大,此时动态优先级的值越大,对应的动态优先级越高,表示进程已经长时间无法获得 CPU 时间了,需要被优先调度运行。
平均睡眠时长和 bonus 的大致关系如下:
| Average sleep time | Bonus |
|---|---|
| 0 <= st < 100ms | 0 |
| 100ms <= st < 200ms | 1 |
| 200ms <= st < 300ms | 2 |
| xxx | xxx |
普通进程的调度除了受到 quantum 和动态优先级的影响外,还和是否是交互式进程有关。进程被判定成交互进程之后:
- quantum 用完后,一般情况下,交互式进程继续留在运行队列,重置时间片。批处理程序直接放入过期队列中。
- 如果最老过期进程等待时间过长,则交互进程也需要直接放入运行队列。
- 如果过期队列存在比交互式进程的静态优先级高的进程,则交互进程也需要直接放入运行队列。
以上这些策略会随不同版本的 linux 内核进行改变,不过它们的设计动机都是比较明显的,尽量减少交互式进程的响应时间和避免进程饥饿。
实时进程调度
实时进程优先级从 1(最高) 到 99(最低),只有静态优先级的概念。有 2 种调度策略:
- SCHED_FIFO: 最高静态优先级的实时进程除非主动让出 CPU 或者死亡,否则会一直运行。
- SCHED_RR: round robin,最高静态优先级的实时进程用完自己的时间片,内核将它放在对应运行队列链表的末尾,保证同一链表中的实时进程能平均获得时间片。
实时进程的抢占时机有以下几个:
- 有更高静态优先级的实时进程出现。
- 进程进入阻塞状态主动让出 CPU。
- 进程停止或者死亡。
- 进程主动调用系统调用 sched_yield() 让出时间片。
- 进程使用 SCHED_RR 策略并且用完时间片。
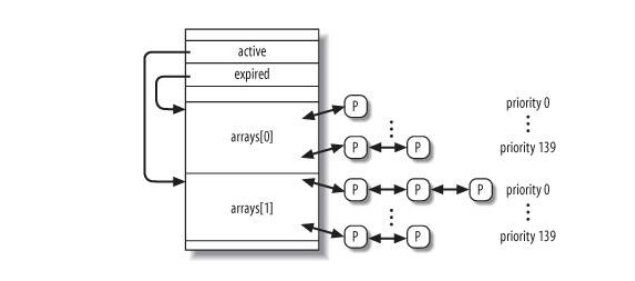
内核中 runqueue 的大致结构如下:
多处理器运行队列的平衡
任务调度的另一类经典问题是任务的不平衡问题,在多处理器机器下,单个 CPU 可能因为存在大量批处理任务,导致对应的运行队列中其他任务出现高延迟,而其他 CPU 上没有可运行任务,所以就有了运行队列的平衡问题。一些任务窃取 worker stealing 的术语也和这个有关。
内核根据超线程技术和 NUMA 提出调度域的层级概念,通过调度域概念抽象出系统的硬件拓扑,更具体一点,就是 CPU 缓存、内存 locality 和节点 interconnect。
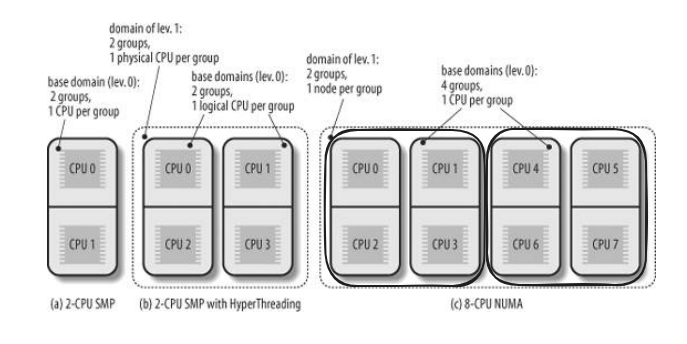
在上面这个例子中,我们观察 picture c:
- level 1 domain 有 2 个 group,分别对应 NUMA 的 2 个 node 节点,node 节点 1 上有 CPU0~CPU3, node 节点 2 上有 CPU4~CPU7。
- level 0 domain 有 4 个 group,每个 group 有 2 个 physical CPU, 比如 CPU0 和 CPU2 同属 1 个 group。
- 在任务迁移时,优先从 level 0 的 group 内迁移,比如从 CPU0 的 runqueue 迁移到 CPU2 的 runqueue,它们有更好的 memory locality;
- 如果不平衡还在加剧,就从 CPU0 的 runqueue 跨 group 迁移到 CPU1 的 runqueue。
- 如果不平衡还在加剧,就从 CPU0 的 runqueue 跨 node 迁移到 CPU4 的 runqueue。
多处理器运行队列平衡还有另外一些更加细致的条件判断进程是否可以迁移到其他的 runqueue。
内核抢占和进程切换
内核抢占
内核抢占是指 CPU 执行内核路径时,是否允许高优先级进程抢占 CPU。这个概念很容易和以下几个概念搞混:
- 用户态切换内核态-中断/异常/系统调用
- 中断/异常嵌套
它们的区别在于:
- 内核抢占只发生在内核态和内核态之间,用户态切内核态是它的前置条件。
- 中断/异常嵌套也是发生在内核态和内核态之间,不同点在于中断嵌套是在同一个进程的 context 下,它们的 current 进程没有变。
为了更好得区分不同的概念和它们的区别,我们举例说明:
- 用户态切内核态
current: Process A
1. Run User code + User Stack
2. A hardware interrupt happens
3. Store User Code context
---------------------------------
3. Run Interrupt Handler + Interrupt Kernel Stack
4. Interrupt Handler finishes
---------------------------------
5. Resume User Code context
6. Run User Code + User Stack
current: Process A(unchanged)
- 中断嵌套
current: Process A
1. Run User code + User Stack
2. A hardware interrupt irq0 happens
3. Store User Code context
-----------------------------------
4. Run Interrupt Handler 0 + Interrupt Kernel Stack
5. A hardware interrupt irq1 happens
6. Store irq0 context
-----------------------------------
-----------------------------------
7. Run Interrupt Handler 1 + Interrupt Kernel Stack
8. Interrupt Handler 1 finishes
-----------------------------------
-----------------------------------
9. Resume irq0 context
10. Run Interrupt Handler 0 + Interrupt Kernel Stack
11. Interrupt Handler 0 finishes
-----------------------------------
12. Resume User Code context
13. Run User Code + User Stack
current: Process A(unchanged)
- 内核抢占
current: Process A
1. User mode -> ... -> kernel mode
2. Process A open kernel preemption
3. Kernel Stack finds a high priority process B
4. Store current kernel context
5. Switch to Process B
current: Process B(changed)
6. CPU chooses Process A again
7. Resume kernel context
current: Process A(changed)
8. kernel mode -> ... -> User mode
current: Process A
进程切换
进程切换指的是 CPU 在不同进程执行流间切换,它的实现基础是硬件中断,比如依赖周期性的时钟硬件中断,CPU 硬件单元几乎可以打断所有当前在 CPU 上执行的逻辑流,除非显式关中断。
关于进程切换,通常有以下几个误解:
- 进程切换和内核抢占 kernel preemption 是一个概念?
不是。
进程切换可以发生在主动让出 CPU 和内核抢占的场景下。
内核抢占是指 CPU 正在运行当前进程的内核路径时(包括中断处理例程、异常处理例程和系统调用例程),是否允许高优先级进程抢占 CPU。 - 进程切换和用户态到内核态的硬件上下文切换是一回事?
不是一回事。它们在时机、内核栈类型和硬件上下文保存上都存在差异。- 时机
进程切换总是发生在内核态,此时可能是当前进程需要等待资源,或者高优先级进程抢占 CPU。
而用户态到内核态切换场景有中断、异常和系统调用,发生在用户态,比如 CPU 处于用户态时中断发生了,是内核切换的前置场景。 - 内核栈类型
进程切换是内核栈到内核栈的切换,这里的内核栈可能是中断内核栈、异常内核栈或者进程内核栈。
用户态到内核态切换是用户态栈到内核栈的切换。 - 硬件上下文保存
用户态切内核态时,部分硬件上下文(cs/esp/eip)由硬件电路完成,一部分(通用寄存器)由软件完成,保存在对应的内核栈中。
进程切换是软件切换机制,硬件上下文保存全部由软件完成,大部分保存在进程描述符的 thread 字段中,通用寄存器等保存在新内核栈中。同时,要考虑保存的硬件上下文更多,比如浮点计算用到的 FPU 寄存器,因为其他进程可能用到,但是内核不会用到。
- 时机
进程上下文切换(context switch)
内核提供了 schedule() 函数进行进程切换,可以被内核控制路径,比如中断处理例程,通过直接或者延迟的方式调用。
- 直接调用:典型例子是用户代码调用系统调用获取系统资源时,在资源不可用的场景下将自己注册到等待队列中,然后主动调用 schedule 让出 CPU 时间。
- 延迟调用:把当前进程的 TIF_NEED_RESCHED 标志设置为 1,在返回用户态之前内核总会检查这个标志,设置了就调用 schedule 进行进程切换。经典场景包括:
- 时钟中断后,检查到 current 进程耗尽了时间片,设置当前进程标志表示应该切换进程。
- 异步硬件事件到达,中断处理例程唤醒特定等待队列中的进程,发现唤醒进程优先级高于 current 进程,设置当前进程标志。
switch_to 宏
进程切换中比较核心的硬件上下文切换操作都在 switch_to 宏中,这也是个相当有意思和细节满满的操作。
macro switch_to(prev, next, last)
// pre: 当前进程 A
// next: 要执行的新进程 B, A->B
// last:进程 A 恢复执行时的 last 进程,也就是上一个进程 C,C->A
有点奇怪的是,本来切换只是 2 个进程的事情—本进程和将要执行执行的新进程,为什么要关注一个 last 进程的东西?
理解 last 进程 C 对理解整个 switch_to 宏的完整工作有重要的意义。
pre 进程 A 和 next 进程 B 在概念上都很好理解,因为它是在进程 A 执行时候就定义的变量,非常符合线性思维。但是 last 进程 C 会有点 tricky,从形式上会凭空出现一个不在进程 A 中定义的东西,是因为 CPU 执行角度的线性视角对于单个进程而言就不是线性的了,CPU 执行是 A->V->E->C->A, 不会是 A->A->A->B->B 这样。所以当 CPU 再次执行进程 A 时,就一定会有个 last 进程 C,进程 A 是从进程 C 切换而来的。
获取进程 C 的引用可以为 last 进程做一些状态更新操作和资源清理工作等等,可以想到的还有是,假如进程 A 是个内核线程,获取进程 C 的引用后还可以借用借用进程 C 的页表了。这个只是假设,没有验证过这个猜想,留做有序的一个小疑问。
让我们深入看具体的 switch_to 的实现:
macro switch_to {
///
/// 以下处于进程 A 的 context, 正在执行进程 A(prev) -> 进程 B(next) 的切换
///
// 1. 将 prev 和 next 的值保存到 eax 和 edx 寄存器
movl prev, %eax
movl next, %edx
// 2. 将 eflag 和 ebp 寄存器的值压入 prev 进程的进程内核栈
pushfl
pushl %ebp
// 3. 将 prev 进程内核栈的栈顶位置保存在 prev->thread.esp 中,484 是 esp 字段相对 prev 指针的 offset
movl %esp,484(%eax)
// 4. 将 next 进程内核栈的栈顶位置加载到 esp 寄存器中
// 注意,从这里开始的栈操作都是针对 next 的内核栈了
movl 484(%edx), %esp
// 5. 将地址标签 1 保存在 prev->thread.eip 中,这是进程 A 恢复执行时将要设置到 eip 的值,也就是恢复后执行的开始地址
movl $1f, 480(%eax)
// 6. 将 next->thread.eip 压入 next 进程内核栈,在大多数情况下这个也是标签 1,因为进程 B 也是调用 switch_to 被切换掉的。
// 这里之所以要把 next 保存的 eip 指压入自己的内核栈,是为了模拟 C 语言函数调用。C 语言在调用一个函数 F 之前,会把函数的下一条指令压入栈,这样函数 F
// 在执行结束,调用 ret 指令的时候,会将栈顶的指令地址 pop 出,放入 eip 中执行。这个算是 CPU 指令的一种硬件约束。
pushl 480(%edx)
// 7. 调用 __switch_to 让出 CPU 时间
// 注意,步骤 7 之后 CPU 就去执行进程 B 的地址标签 1 的代码,而下面的代码是进程 A 的地址标签 1 代码,需要等到再切换回进程 A 才会继续往下执行。
jmp __switch_to
///
/// 以下处于进程 A 的 context,正处于进程 C 切换进程 A 的结尾,此时 eip 和 esp 已经被切换成了进程 A 的上一个硬件上下文状态了
///
// 8. 进程 A 恢复执行后,从地址标签 1 开始执行
// 这里,从这里开始已经是进程 A 的进程内核栈了,因为进程 C -> 进程 A 的过程中,在步骤 4 的时候,进程 A 作为 next 进程,其在 thread 中保存 eip
// 值在步骤 4 的时候加载到了 esp 寄存器中,在步骤 7 中被切换到进程 A。此时 CPU 才会执行到标签 1 的位置。
1:
// 做和步骤 2 相反的操作,pop 出 ebp 和 eflag 寄存器的值,恢复进程 A 的现场
popl %ebp
popfl
// 9. 这里非常 tricky, 注意这里的 eax 的值并不是进程 A context 下 prev,而是进程 C context 下 prev 值,也就是进程 C 的进程描述符地址。
// 之所以这样做,其实是严格约束了进程切换的实现不要丢失 eax 值,这样才能保存下进程 C 的引用。
movl %eax, last
}
_ _switch_to(struct task_struct *prev_p, struct task_struct *next_p) _ _attribute_ _(regparm(3)) {
// 1. 延迟保存浮点寄存器的值,如果进程 A 和进程 B 都不会用到浮点寄存器,那就没必要保存
__unlazy_fpu(prev_p);
// 2. 获取当前 CPU id,并把进程 B 的 esp0 值保存在 init_tss 对应 CPU 位置下。在用户态切内核态的博客中,我们提及了中断发生时,CPU 硬件单元会读取 TSS
// 段的 esp 值,从而从用户态栈切换到一个高权限的中断内核栈。从这里也可以看出,在真正执行进程 B 之前,tss 段中中断内核栈的栈顶就已经给正确更新了。
cpu=smp_processor_id();
init_tss[cpu].esp0 = next_p->thread.esp0;
...
// tls related ops
...
// 3. 加载进程 B 的 thread 字段中的寄存器值到寄存器中,恢复进程 B 的硬件上下文
...
// 4. 翻译成以下 2 条汇编,恢复进程 A 的地址到 eax 寄存器,这是 switch_to 的约定
// ret 指令相对于将此时栈顶弹出,并设置到 eip 寄存器中,此时 CPU 开始执行进程 B 的地址标签 1 的代码
// movl %edi,%eax
// ret
return prev_p;
这一系列博客的意图都是希望从线性的角度让读者了解内核和内核中的一系列抽象概念,但是 switch_to 流程是少见的非线性逻辑,在一个函数中出现了另外一个进程 C 的上下文。所以我们通过图示的方式进一步解释整个流程,
让读者能感受下这里的实现魅力。
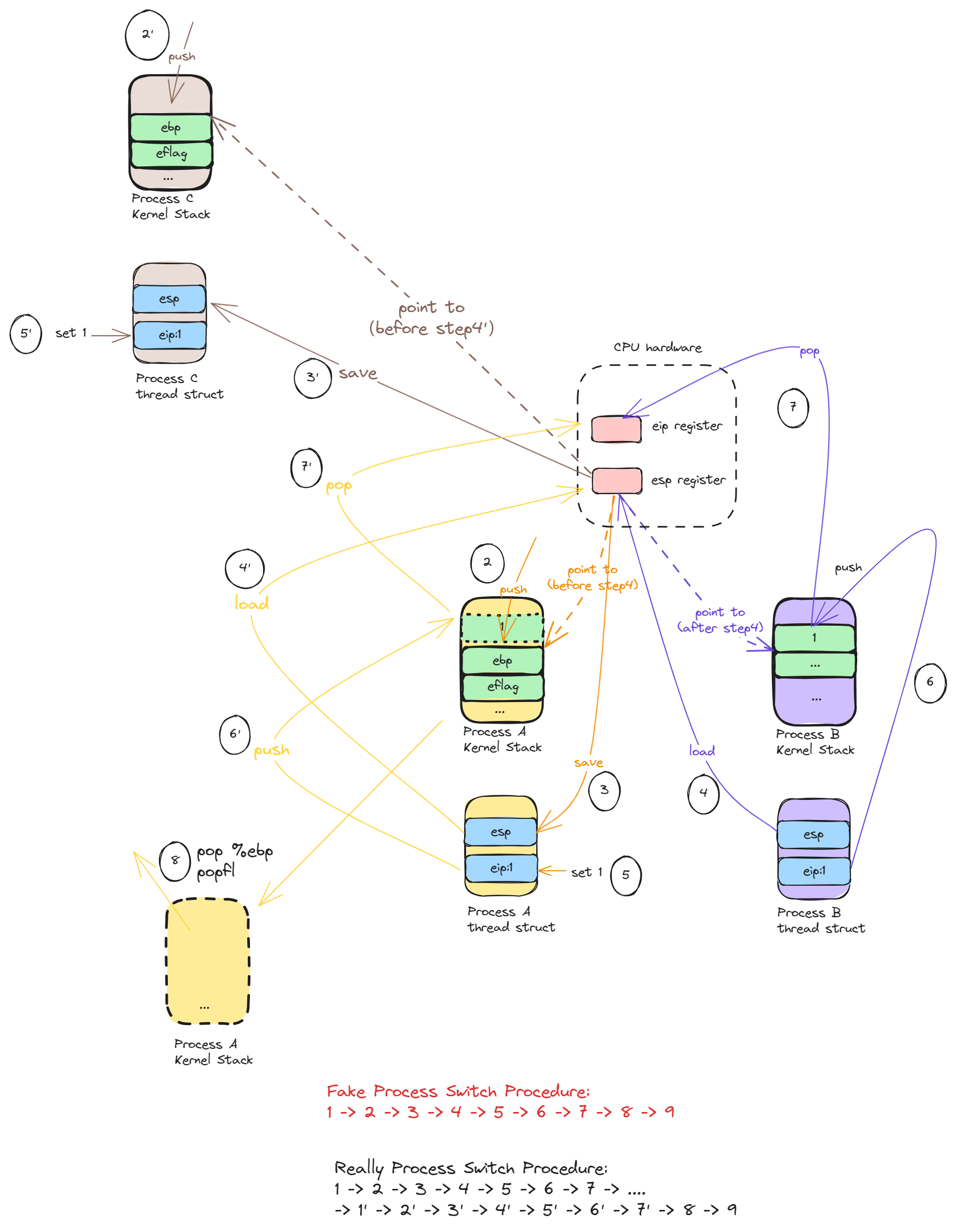
source
这个图这么复杂看起来不是一个很好的表达方式,以后想到更好的方式再替换。
理解进程切换的关键还是在于从进程 A 的步骤 7 到步骤 8 不是线性的,中间隔着很多次进程切换。然后再从进程 C 的步骤 1’到步骤 7‘,之后才是步骤 8,此时才真正回到进程 A 的上下文。 current。
总结
通过对进程切换和进程优先级模型的描述,我们大致了解了内核中 CPU 是如何在不同的执行流间切换的,大致总结成以下几个特点:
- 内核依赖硬件时钟中断实现分时复用机制,所有的进程切换都发生在内核态。
- 进程切换依赖内核对进程硬件上下文的保存和恢复机制。
- 内核使用优先级调度模型,每个进程拥有静态优先级和动态优先级,同时被分类成不同类型进程,比如实时进程,交互进程和批处理进程。
- 进程的静态优先级决定时间片长短,动态优先级由进程静态优先级和进程平均休眠时间按经验公式计算出来,并被动态调整到不同的优先级队列中。
我们再从整体描述下这个过程,承接 Manage Processes, 以便读者以线性的思维感受下操作系统的运行。
- 硬件加电后内核被 bios 加载到物理内存。
- CPU 开始执行内核初始化例程,其中初始化了进程链表和运行队列等核心数据结构,并创建了进程 0 和其他内核线程。
- 内核完全初始化之后,就可以通过系统调用的方式向内核注册用户进程,比如 shell、terminal 和图像界面等程序。
- 通过硬件中断,比如周期性时钟中断和网卡中断等,再加上内核对进程优先级的调整,CPU 不断在中断处理例程、内核线程、进程逻辑等之间跳转。