
TiCDC is a change data capture tool for TiDB, an open-source, distributed SQL database. TiCDC captures data changes from TiKV and synchronizes them downstream. This article discusses TiCDC’s data parsing implementation and the TiDB Online DDL mechanism.
Background and Problem
Data replication components are indispensable tools in the database ecosystem. For example, the well-known open-source single-node database MySQL includes data replication as part of its server capabilities and implements asynchronous/semi-synchronous/synchronous master-slave replication based on MySQL binlog. Due to MySQL’s pessimistic transaction model and table metadata locks, we can always assume that the data and schema with causal relationships in the MySQL binlog follow the chronological order, i.e.:
New data commitTs > New schema commitTs
However, for TiDB’s storage-compute separation architecture, schema changes are persisted at the storage layer, and service layer nodes act as multiple cache nodes, always having a period of schema inconsistency. To ensure data consistency and achieve online DDL changes, existing distributed databases mostly adopt or refer to the Online, Asynchronous Schema Change in F1 mechanism. Therefore, the question we need to answer becomes, under the TiDB Online DDL mechanism, how does TiCDC correctly handle the correspondence between data and schema, and whether the data and schema with causal relationships still satisfy:
New data commitTs > New schema commitTs
To answer this question, we first need to explain the core principles of the original F1 Online Schema Change mechanism, then describe the current TiDB Online DDL implementation, and finally discuss the handling relationship between data and schema in the current TiCDC implementation and the different exceptional scenarios that may arise.
F1 Online Schema Change
The core problem that the F1 Online Schema Change mechanism aims to solve is how to achieve online schema changes that ensure data consistency in a single-storage, multi-cache node architecture, as shown in Figure 1:
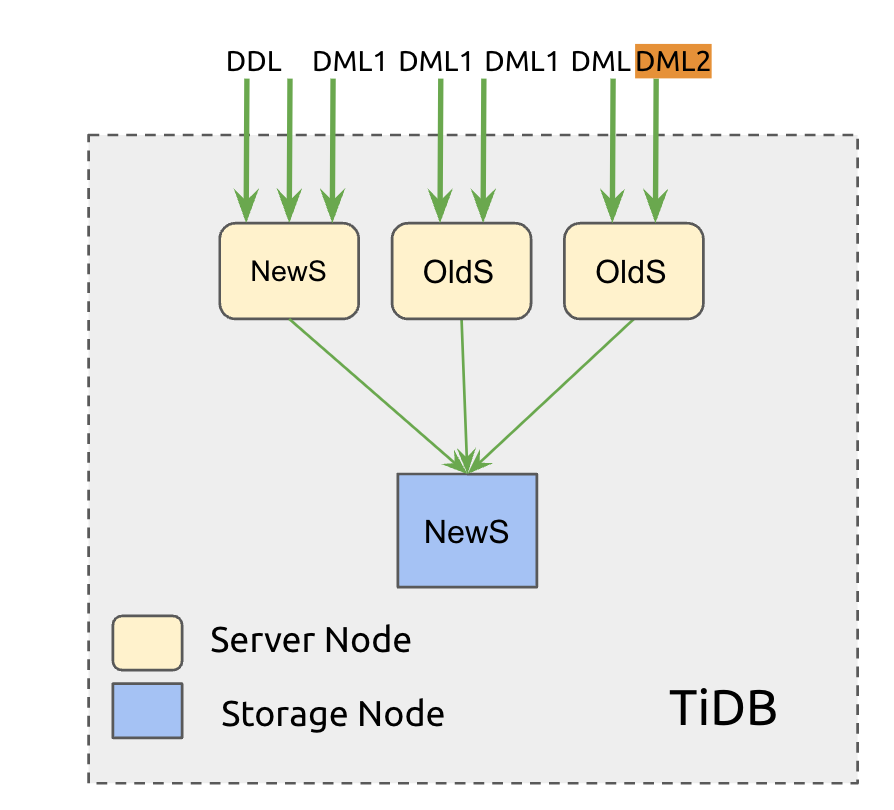
Figure 1: Schema changes in a single-storage, multi-cache node architecture
The original paper defines data inconsistency issues as orphan data anomaly and integrity anomaly. If orphan data or integrity anomalies appear after schema changes, we consider the data inconsistent. The characteristics of schema change issues in such systems can be summarized into the following three points:
- One schema storage, multiple schema caches
- Some new schemas and old schemas cannot coexist
- When directly changing from the old schema to the new schema, there is always a time period when both exist simultaneously
- Characteristics 1 and 3 are caused by the system architecture and are relatively easy to understand. A typical example of characteristic 2 is adding an index. When a service layer node with the new schema inserts data, it will also insert the index, while a service layer node with the old schema will only delete data during deletion, leading to orphan indexes and data redundancy.
- Characteristics 2 and 3 of schema change issues seem to be a contradictory deadlock: the new schema and old schema cannot coexist, but they must coexist. The F1 Online Schema mechanism provides a clever solution by changing the conditions since the result cannot be changed. The main ideas of this solution are shown in Figure 2:

Figure 2: F1 Online DDL solution
- Introduce intermediate schema states that can coexist, such as
S1->S2'->S2, where S1 and S2’ can coexist, and S2’ and S2 can coexist; - Introduce a definite isolation time interval to ensure that schemas that cannot coexist do not appear simultaneously; Specifically:
- Introduce intermediate schema states that can coexist
Since directly changing from schema S1 to schema S2 causes data inconsistency issues, intermediate states like delete-only and write-only are introduced, changing the process from
S1 -> S2toS1 -> S2+delete-only -> S2+write-only -> S2. The lease mechanism ensures that at most two states coexist simultaneously. By proving that each pair of adjacent states can coexist and ensure data consistency, we can deduce that the data remains consistent throughout the transition from S1 to S2. - Introduce a definite isolation time interval Define schema lease, and after the lease duration, nodes need to reload the schema. If nodes cannot obtain the new schema after the lease duration, they go offline and stop providing services. This allows us to define a clear time boundary: after 2*lease duration, all nodes will update to the next schema.
Introducing Coexisting Intermediate States
What kind of intermediate states do we need to introduce? That depends on the problems we need to solve. Here, we still use the add index DDL as an example; details of other DDLs can be found in the Online, Asynchronous Schema Change in F1 paper.
Delete-only State
We can see that the old schema cannot see the index information, which leads to the scenario where data is deleted, leaving behind orphan indexes. Therefore, the first intermediate state we need to introduce is the delete-only state, which gives the schema the ability to delete indexes. In the delete-only state, the schema can only delete indexes during delete operations and cannot operate on indexes during insert/select operations, as shown in Figure 3:
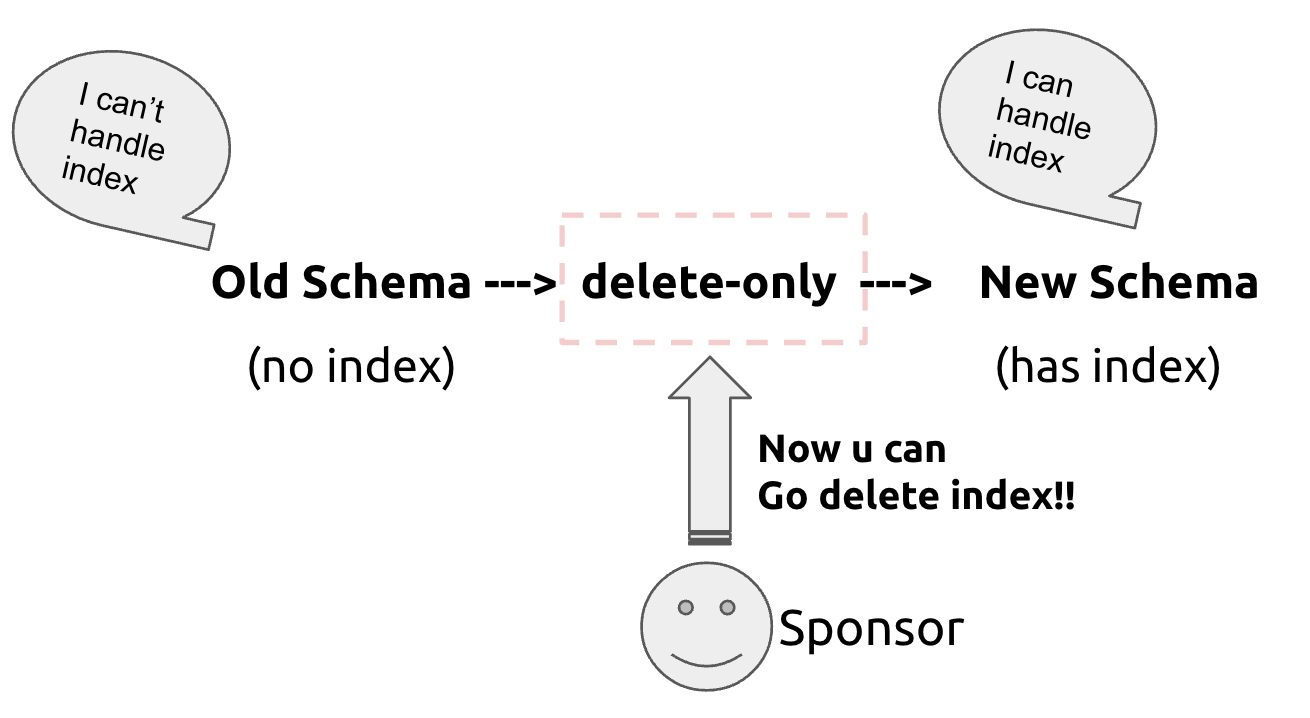
Figure 3: Introducing the delete-only intermediate state
The original paper defines delete-only as follows:

Assuming we have introduced a definite isolation time interval (which will be detailed in the next section), ensuring that at most two schema states appear simultaneously. So, after introducing the delete-only state, the scenarios we need to consider become:
1. old schema + new schema(delete-only)
2. new schema(delete-only) + new schema
- For scenario 1, all service layer nodes are either in the old schema state or in the new schema(delete-only) state. Since the index can only be operated on during delete operations, no index is generated, avoiding the issue of orphan indexes and ensuring data consistency. We can say that the old schema and new schema(delete-only) can coexist.
- For scenario 2, all service layer nodes are either in the new schema(delete-only) state or in the new schema state. Nodes in the new schema state can normally insert and delete data and indexes, while nodes in the new schema(delete-only) state can only insert data but can delete data and indexes. This results in some data missing indexes, leading to data inconsistency.
Introducing the delete-only state solves the issue of orphan indexes, but nodes in the new schema(delete-only) state can only insert data, leading to new data and historical data missing index information, resulting in data inconsistency.
Write-only State
In scenario 2, we see that for scenarios like add index, nodes in the new schema(delete-only) state have missing indexes for new and historical data. Historical data is finite and can be indexed within a limited time, but new data may increase over time. To solve this issue, we need to introduce a second intermediate state, the write-only state, which gives the schema the ability to insert/delete indexes. Nodes in the write-only state can insert/delete/update indexes but cannot see indexes during select operations, as shown in Figure 4:
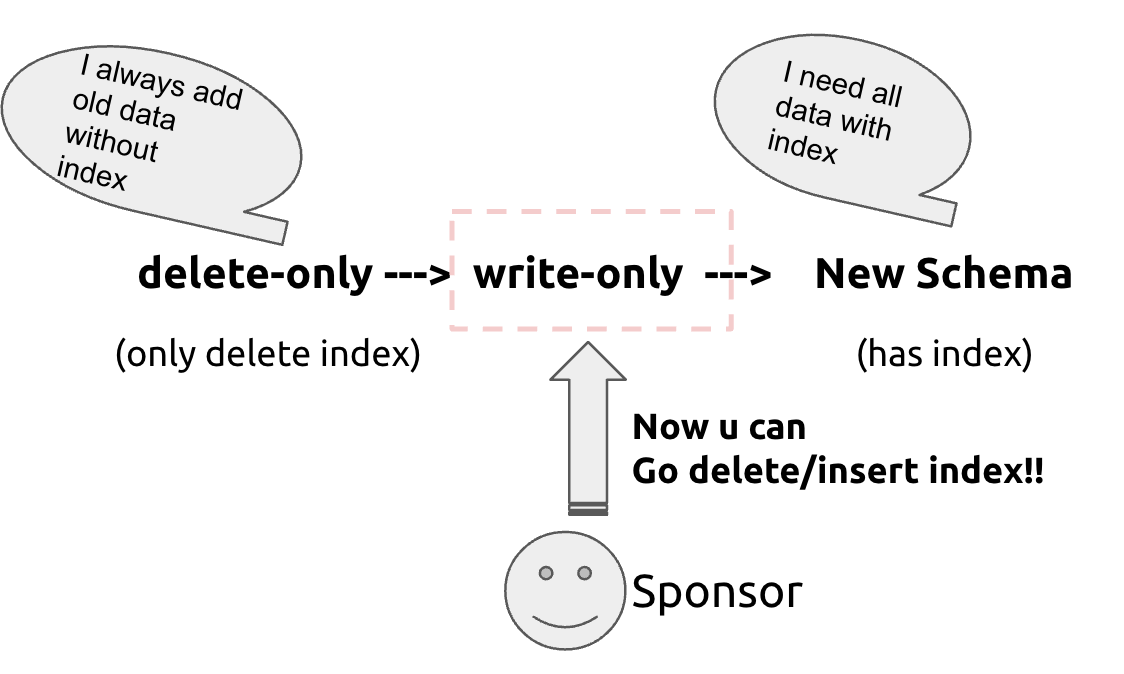
Figure 4: Introducing the write-only state
The original paper defines write-only as follows:

After introducing the write-only state, scenario 2 is split into scenario 2’ and scenario 3:
2': new schema(delete-only) + new schema(write-only)
3: new schema(write-only) + new schema
- For scenario 2’, all service layer nodes are either in the new schema(delete-only) state or in the new schema(write-only) state. Nodes in the new schema(delete-only) state can only insert data but can delete data and indexes, while nodes in the new schema(write-only) state can normally insert and delete data and indexes. Although there are still missing indexes, since indexes are invisible to users in both delete-only and write-only states, users only see complete data, ensuring data consistency.
- For scenario 3, all service layer nodes are either in the new schema(write-only) state or in the new schema state. New data can maintain indexes normally, while historical data still has missing indexes. Since historical data is finite, we can complete the index for historical data after all nodes transition to the write-only state and then transition to the new schema state, ensuring complete data and indexes. Nodes in the write-only state see complete data, while nodes in the new schema state see complete data and indexes, ensuring data consistency for users.
Section Summary
Through the description of the delete-only and write-only intermediate states, we see that in the F1 Online DDL process, the original single-step schema change is separated by two intermediate states. Each pair of states can coexist, ensuring data consistency at each state change and throughout the entire process.
Introducing a Definite Isolation Time Interval
To ensure that at most two states exist simultaneously, we need to stipulate the behavior of service layer nodes loading schemas:
- All service layer nodes need to reload the schema after the lease period;
- If they cannot obtain the new schema within the lease period, they go offline and stop providing services;
By stipulating the behavior of service layer nodes, we can define a clear time boundary: after
2*leaseduration, all normally functioning service layer nodes can transition from schema state1 to schema state2, as shown in Figure 5:
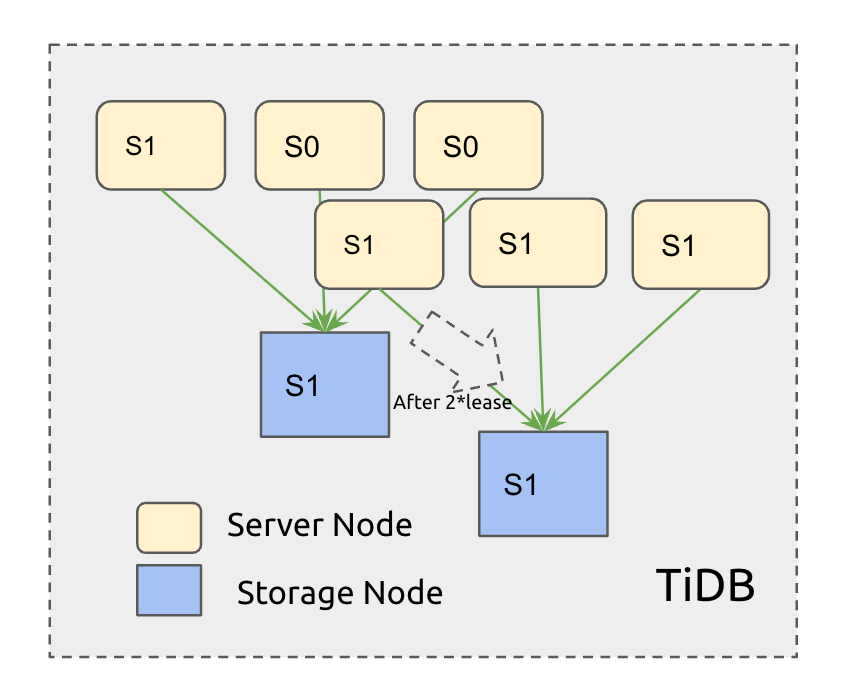
Figure 5: All nodes can transition to the next state within 2*lease duration
Intermediate State Visibility
To correctly understand the intermediate states in the original paper, we need to understand the visibility of intermediate states. In previous sections, we used add index as an example to describe that indexes are invisible to users in delete-only and write-only states. However, in the write-only state, delete/insert operations can operate on indexes. If the DDL is changed to add column, can users insert explicitly specifying the new column when nodes are in the write-only state? The answer is no. In general, the visibility of delete/insert in intermediate states is internal visibility, specifically service layer nodes’ visibility to storage layer nodes, not user visibility. For add column DDL, service layer nodes can see the new column in delete-only and write-only states but are restricted in operations. Users can only see and operate on the new column in the new schema state, as shown in Figure 6:
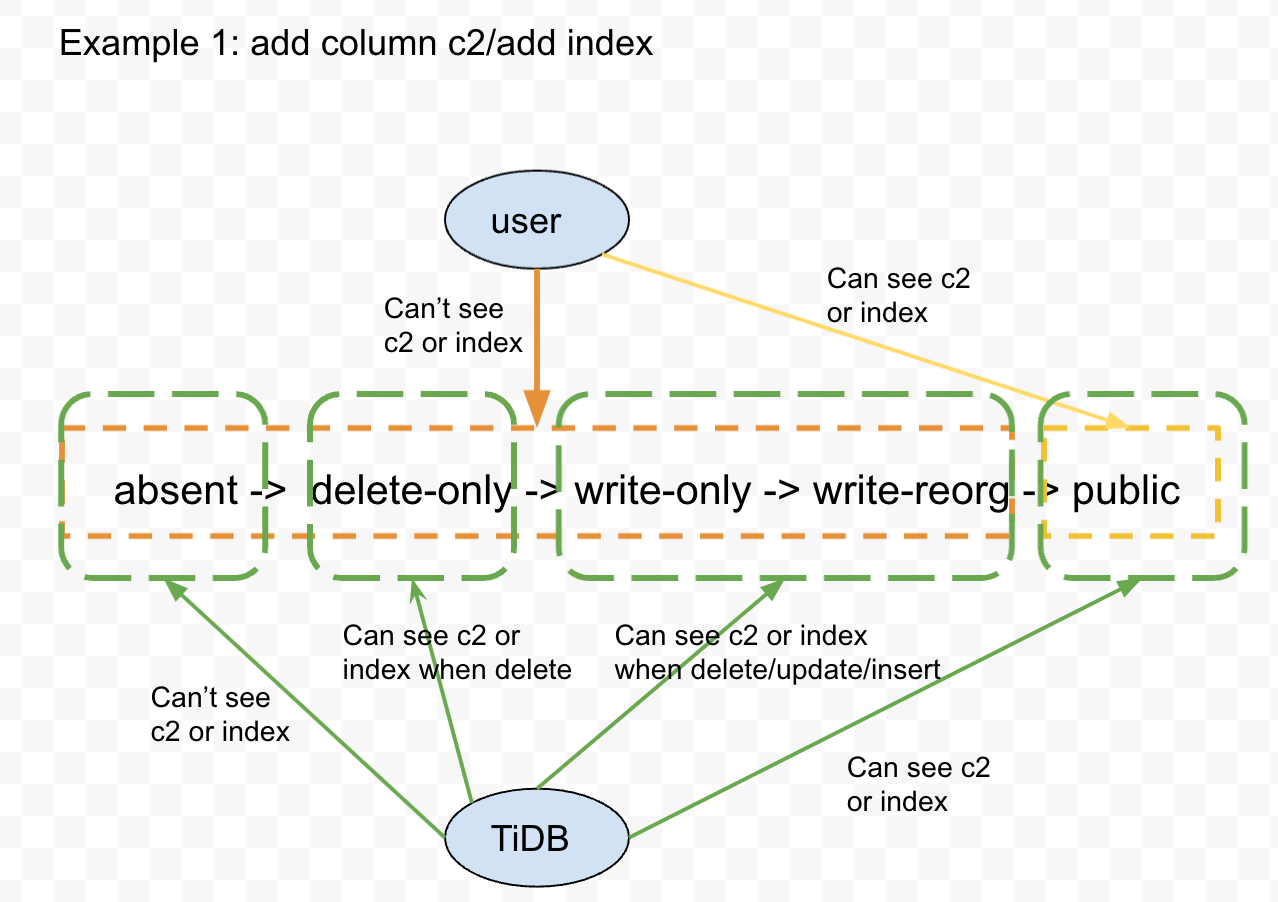
Figure 6: Intermediate state visibility
To clearly describe visibility, let’s use an example, as shown in Figure 7. The original table columns are <c1>, and after the DDL operation, the table columns are <c1,c2>.


Figure 7: Intermediate state transition
- In small figure (1), service layer nodes have transitioned to scenario 1, with some nodes in the old schema state and some in the new schema(delete-only) state. At this point, c2 is invisible to users, and explicit insert<c1,c2> or delete<c1,c2> operations specifying c2 fail. However, storage layer data like [1,xxx] can be deleted, and only rows like [7] missing c2 can be inserted.
- In small figure (2), service layer nodes have transitioned to scenario 2, with some nodes in the new schema(delete-only) state and some in the new schema(write-only) state. At this point, c2 is still invisible to users, and explicit insert<c1,c2> or delete<c1,c2> operations specifying c2 fail. Nodes in the write-only state will internally fill default values for insert [9] to [9,0] in the storage layer. Nodes in the delete-only state will convert delete [9] to delete [9,0].
- In small figure (3), after all service layer nodes transition to the write-only state, c2 is still invisible to users. At this point, data filling begins, filling rows missing c2 in historical data (implementation may vary, such as marking in the table’s column information).
- In small figure (4), transitioning to scenario 3 begins, with some nodes in the new schema(write-only) state and some in the new schema state. Nodes in the new schema(write-only) state still see c2 as invisible to users. Nodes in the new schema state see c2 as visible to users. Users connected to different service layer nodes may see different select results, but the underlying data is complete and consistent.
Section Summary
In the previous three sections, we briefly described the F1 online Schema mechanism. The original single-step schema change is broken down into multiple intermediate change processes, ensuring data consistency while achieving online DDL changes.
For add index or add column DDL, the state changes are as described above. For drop index or drop column, the process is completely reversed. For example, in the drop column state, the column becomes invisible to users in the write-only stage and beyond, but internally, it can be correctly inserted/deleted, with visibility being the same as previously discussed.
TiDB Online DDL Implementation
TiDB Online DDL is based on the F1 Online Schema mechanism, and the overall process is shown in Figure 8:

Figure 8: TiDB Online DDL Process
The process can be briefly described as follows:
- When a TiDB Server node receives a DDL change, it wraps the DDL SQL into a DDL job and submits it to the TiKV job queue for persistence;
- The TiDB Server node elects an Owner role, which fetches the DDL job from the TiKV job queue and is responsible for executing the multi-stage DDL change;
- Each intermediate state of the DDL (delete-only/write-only/write-reorg) is a transaction commit, persisted in the TiKV job queue;
- After the schema change is successful, the DDL job state changes to done/sync, indicating that the new schema is officially visible to users. Other job states like cancelled/rollback done indicate schema change failure;
- During the schema state change process, the etcd subscription notification mechanism is used to speed up schema state synchronization among server layer nodes, shortening the
2*leasechange time; - After the DDL job is in the done/sync state, it indicates that the DDL change has ended and is moved to the job history queue;
For detailed TiDB processing flow, refer to: Detailed TiDB processing flow and TiDB DDL Documentation
Data and Schema Handling Relationship in TiCDC
Earlier, we described the principles and implementation of the TiDB Online DDL mechanism. Now we can return to the initial question: under the TiDB Online DDL mechanism, can we still satisfy:
New data commitTs > New schema commitTs
The answer is no. In the description of the F1 Online Schema mechanism, we can see that in the add column DDL scenario, when service layer nodes are in the write-only state, they can already insert new column data, but the new column is not yet visible to users. This results in New data commitTs < New schema commitTs, or the above conclusion becomes:
New data commitTs > New schema(write-only) commitTs
However, during the delete-only + write-only transition state, TiCDC directly uses the New schema(write-only) as the parsing schema, which may cause data inserted by delete-only nodes to lack corresponding column metadata or have mismatched metadata types, leading to data loss. To ensure correct data parsing, a complex schema strategy may need to be maintained internally based on different DDL types and specific TiDB internal implementations. In the current TiCDC implementation, a simpler schema strategy is chosen, directly ignoring intermediate states and only using the schema state after the change is complete. To better illustrate the different scenarios that TiCDC needs to handle under the TiDB Online DDL mechanism, we use a quadrant diagram for further classification and description.
| Old schema | New schema | |
|---|---|---|
| Old schema data | 1 | 2 |
| New schema data | 3 | 4 |
- 1 corresponds to the old schema state, where old schema data matches the old schema;
- 4 corresponds to the new schema public and beyond, where new schema data matches the new schema;
- 3 corresponds to the write-only ~ public transition
At this point, TiCDC uses the old schema to parse data, but TiDB nodes in the write-only state can already insert/update/delete some data based on the new schema, so TiCDC will receive new schema data. The handling effect varies with different DDLs. We select three common representative DDLs as examples.
- add column: State changes
absent -> delete-only -> write-only -> write-reorg -> public. Since new schema data is filled with default values by TiDB nodes in the write-only state, it will be directly discarded when parsed with the old schema, and the downstream will refill default values when executing the new schema DDL. For dynamically generated data types, such as auto_increment and current timestamp, this may lead to data inconsistency between upstream and downstream. - change column: Lossy state changes
absent -> delete-only -> write-only -> write-reorg -> public, such as int to double, where different encoding methods require data redo. In the TiDB implementation, lossy modify column generates an invisible new column, and both old and new columns are updated simultaneously in intermediate states. For TiCDC, it only processes the old column and then executes the change column downstream, consistent with TiDB’s handling logic. - drop column: State changes
absent-> write-only -> delete-only -> delete-reorg -> public. In the write-only state, newly inserted data no longer has the corresponding column, and TiCDC will fill default values and send them downstream. After executing the drop column downstream, the column will be discarded. Users may see unexpected default values, but the data will meet eventual consistency.
- add column: State changes
- 2 corresponds to directly transitioning from the old schema to the new schema This indicates that under such schema changes, the old schema and new schema can coexist without intermediate states, such as truncate table DDL. After TiDB executes truncate table successfully, service layer nodes may not have loaded the new schema yet and can still insert data into the table. This data will be filtered out by TiCDC based on tableid, ensuring that the table does not exist in both upstream and downstream, meeting eventual consistency.
Summary
As the data synchronization component of TiDB, the correctness of data parsing is the core issue to ensure data consistency between upstream and downstream. To fully understand the various exceptional scenarios encountered in TiCDC’s handling of data and schema, this article first describes the principles of the F1 Online Schema Change mechanism in detail, then briefly describes the current TiDB Online DDL implementation, and finally discusses the handling relationship between data and schema in the current TiCDC implementation.
In conclusion, understanding the F1 Online Schema Change mechanism and TiDB’s implementation helps in grasping how TiCDC manages schema changes and ensures data consistency. By addressing the challenges of schema and data handling, TiCDC maintains reliable data synchronization across distributed systems.