
为了更好得设计 Tiflow engine 的资源管控能力,我阅读了《Understanding The Linux Kernel》和思考了 Linux Kernel 关于资源管理的抽象,
- 越要提高资源利用率,越要将资源切小
- 越要提高资源管控能力,越要提供整体化视图
背景
最近团队在开发一个数据迁移的统一资源调度平台 Tiflow Engine,以便统一抽象 Data Platform 团队多个产品的资源调度能力和 Failover 能力。从 DP 产品能力上看,我们其实希望 Tiflow Engine 的最终形态是类似 Flink 这种流式计算框架,通过统一的流式算子抽象和 UDF 构建端到端的数据库同步流。至于为什么不直接使用 Flink 而是重新造一个轮子,这里有技 术栈的问题,也有已有业务改造成本问题。我们希望通过制定 Roadmap 逐步构建具备良好流式抽象和 Cloud Native 特性的产品。这个 Blog 的 目的不是讨论 Tiflow Engine,而是我在思考我们要做的最终东西的过程中想到的关于 Linux Kernel 的问题。
简单背后的抽象和封装
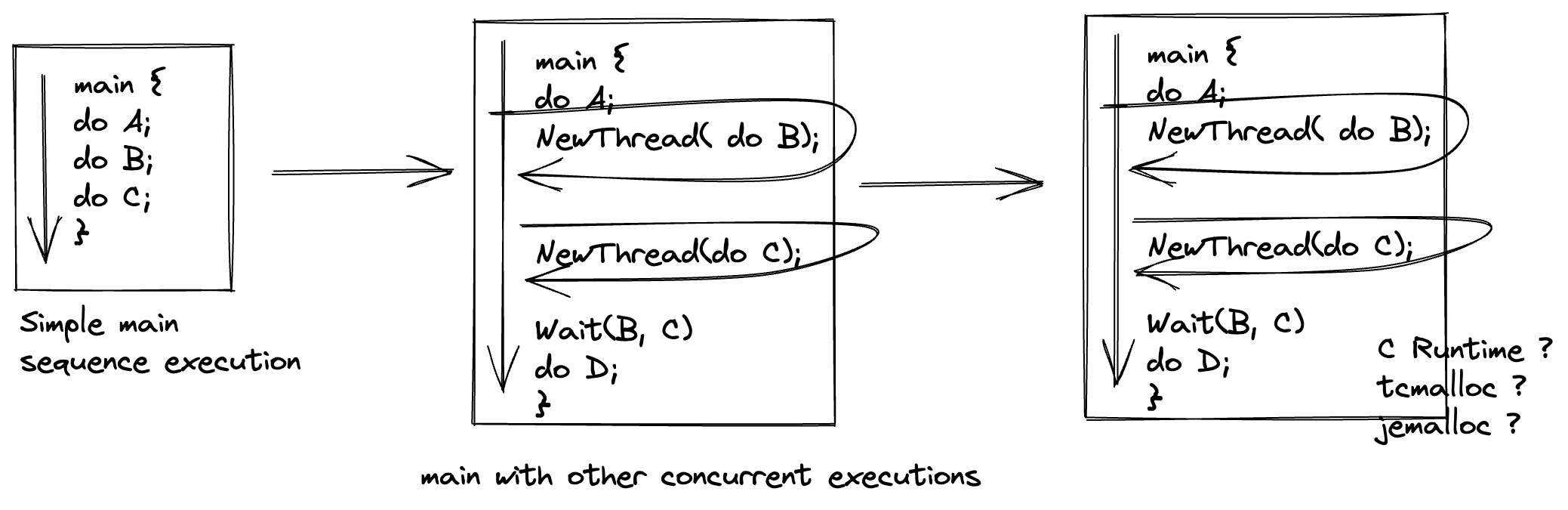
最开始从 main 函数开始写代码的时候,我觉得写的代码在逻辑上是一个很容易理解的东西。从 main 函数入口开始顺序执行,中间调用各种函数,
直到退出 main 函数结束,我完成了我想要做的事情。再复杂一点就是创建一些并行的线程,加上一些锁。然后这样写了两年代码之后,我发现
了一些难以理解的事情,会有一个 C Runtime Lib 的东西和很多复杂的数据结构设计,比如 malloc 效率不高需要使用 tcmalloc 或者 jmalloc,
深入里面看就是各种每线程变量 + 多级内存池。可以理解,但不完全理解,我总觉得这些设计背后有些内容我没有 Get 到。
 source
source
后来深入去找这些问题的答案时,我发现原来这些问题的背后都是抽象和封装的问题。现代高级语言和操作系统提供了非常高级的抽象和封装,以 至于我们使用 C/C++ 这类高级语言写逻辑时,总认为我们处于一个纯粹简单的上下文环境中(我们的代码是从头顺序执行到结束)。满足快速开发 的需求,但却让人不理解这是个什么东西。
从我们编写的高级语言到 CPU 真正执行的机器指令,中间隔了语言运行时、编译器、链接器、装载器、可执行文件格式、操作系统进程管理、地址空间映射、 运行队列、进程切换,才可能到我们编写的 main 函数执行。原来我们写的代码经过了这么长的链路才能被真正执行,那如果我要优化我写的程序,我就有点 崩溃了。
- 如果我不能真正了解整个链路,我要怎么确保我的优化是合理且有效的。
- 在这么多设计中,我如何知道我的设计在原理上是更好的,我做到了可能最好了吗?
说的有点远了,像链接装载器和可执行文件格式,背后更多的是关于格式的约定和模块的复用(链接器背后已经涉及到线性地址空间的文件映射了)。我们在这 一系列博客主要讨论 Linux Kernel 中的资源抽象。
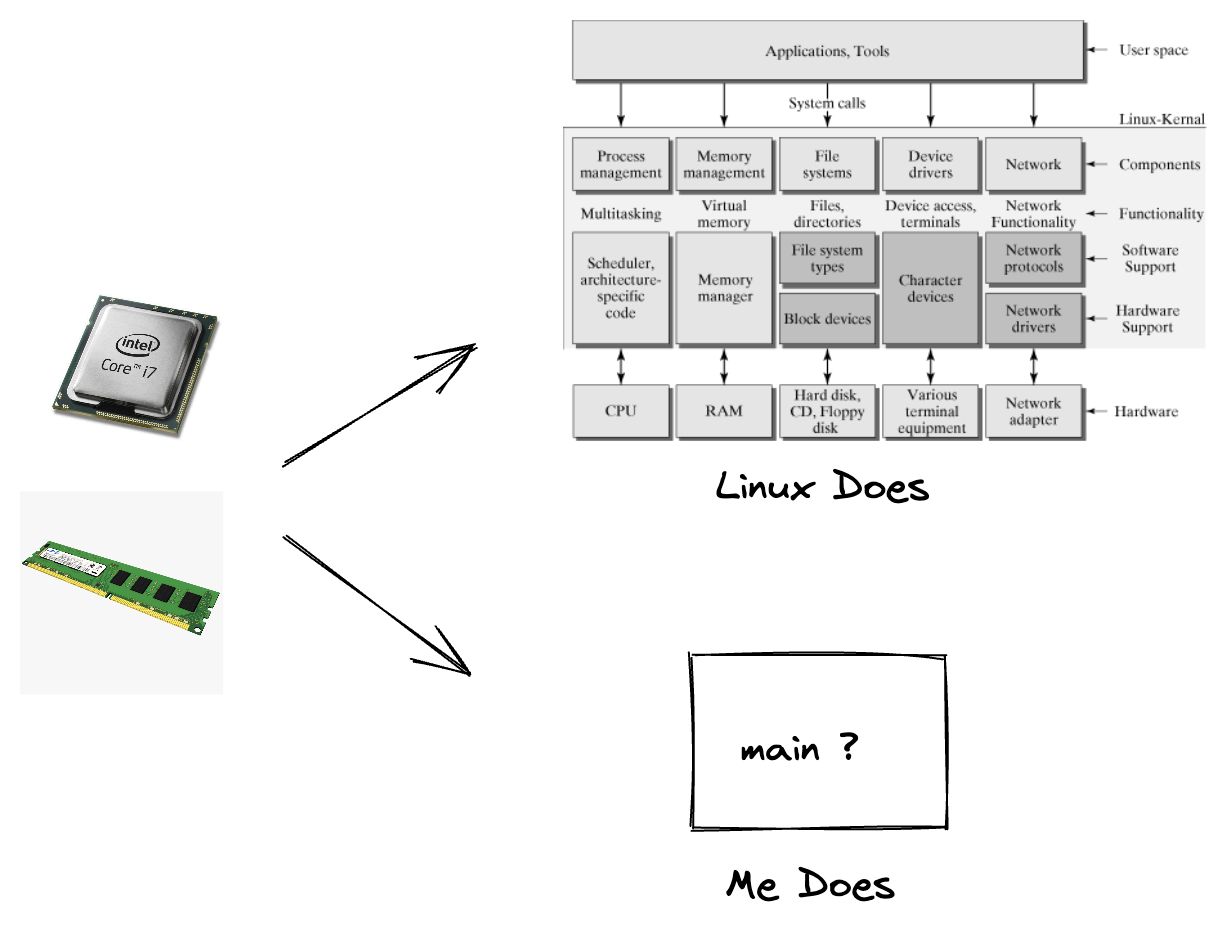
Linux Kernel 中的 内存/CPU 抽象
写过高级语言的同学一开始除了接触语言提供的语法之外,另外一个需要重点理解的是进程关于堆和栈的概念—函数调用用栈,小空间用栈,大空间用堆。再深入 问就是:
- 为什么要抽象出堆和栈的概念?
- 堆和栈在实现上是什么?
- 为什么同样都是拿到一个 4G 地址空间中的一个地址,会是不一样的呢?
于是我们遇到了 Linux Kernel 关于内存资源的抽象。另一方面,从我们写代码的角度看,代码被顺序不间断得执行,遇到阻塞的 I/O 时执行流会等待,然后恢复, 多么符合线性思考习惯,一个好的执行流抽象就应该要做到这种程度。但是再深入思考:
执行流会等待然后恢复具体是什么意思呢?- 具体底层实现是什么样子的?
于是我们遇到了 Linux Kernel 关于 CPU 资源的抽象。还有就是关于 IO 的抽象,以后我们再补充。
Linux Kernel 做了什么
为了了解 Linux Kernel 关于 CPU 和内存资源的抽象,我阅读了《Understanding The Linux Kernel》这本书,内核中各种精巧的数据结构/高效率缓存设计/寄存器
使用总是让我写上一句天才的旁白。
后来我问了自己,在一堆复杂设计的背后,内核真正做的是什么?如果让我来实现内核的话,我会实现成什么样子?这个问题有点恐怖,我拿到的是什么?我拿到的是:
- 一个能被时钟信号驱动不断去取指令顺序执行的 CPU
- 物理空间从 0 到 N 线性寻址的内存硬件
这就有点类似做算法题,给你一段 0~N 的内存地址空间,请从头实现一个高级高效的内存分配器,要怎么设计数据结构?怎么存储内存分配器的元数据?怎么组织可用
的内存空间?原来我和内核面对的是同样简单设计的硬件结构,内核却已经在这样简单可理解的硬件上面,提供了 CPU 分时复用和线性地址空间这样超级高效的资源利用
抽象和封装,关键的关键还是写代码的人甚至在不知道这些抽象的情况下,都可以完成一些简单的工作。
 source
source
想到这里,Linux Kernel 关于资源利用的抽象真是令人佩服。
总结和感悟
对于 Linux Kernel 对资源管理的抽象,一个深刻的感悟就是:
- 越要提高资源利用率,越要将资源切小
- 比如 CPU 的分时复用,对于非 CPU 密集型任务而言,将 CPU 时间切分成小段的时间片,通过在任务等待资源时切换到其他任务运行,提高系统对 CPU 资源的利用率
- 比如进程线性地址空间和操作系统的分页管理,将硬件内存空间切分成小份的内存页,只有进程真正使用内存的时候才分配物理内存页,对于冷数据将物理内存页置换到 文件中,提高了系统对于内存资源的利用率
- 越要提高资源管控能力,越要提供整体化视图
- 比如进程线性地址空间管理,如果将操作系统的内存分页管理暴露给用户,用户将要面对页级别的大量小块内存各种权限/Dirty 属性之类的管理,这对使用者来说就是 灾难。所以进程地址空间其实是引入了更大的整体化视图,比如整个 4G 的连续的线性地址空间,不同特性的线性段,比如只读的代码段,可读可写的数据段,栈,堆, 高 4G 的内核线性区间。通过大的分段设计,可以更加简单得完成资源的统一的管理,比如根据线性地址段的特权级和权限设置页表级别的特权级和权限。
推荐阅读
想要了解更多相关内容,请直接阅读:
- 《Understanding The Linux Kernel》Daniel P.Bovet & Marco Cesati
- 《Modern Operating System》Andrew S.Tanenbaum & Herbert Bos
- 内核源码 https://www.kernel.org/