
从今天开始我们会讲 Linux Kernel 内存管理相关的内容,因为这部分比较庞杂,有些设计上的考量没有完全搞清楚,所以会长期处于 WIP 状态。
奇怪的段寄存器
如果你之前看过一些 Linux Kernel 内存管理和内核源码,你会看到类似下面这种汇编指令片段:
movl $(__KERNEL_DS),%eax
movl %eax,%ds
movl %eax,%es
这里的 ds 和 es 是两个段寄存器。这是我们不太熟悉的概念,可以说进程线性地址空间和分页管理还比较好理解,最终我们都能拿到一个整数的 地址值。CPU 直接将整数的物理地址放在通用寄存器中,然后通过内存总线对内存硬件进行寻址就行,为什么要搞出段寄存器的概念?讲述内存管理 是从我们最不熟悉的段概念开始。接下来我们开始问比较核心的问题—地址是什么。
地址是什么
对某些人来说,这个问题问得有些奇怪—地址就是地址,是个大整数,为什么要问地址是什么这么无聊的问题。的确,如果你使用 C/C++ 这种直接
操作指针管理内存的语言,使用 printf 打印出某个指针的地址时,你会看到一个大整数,或者一个 0x 开头的 16 进制整数。在 32 bit 机器上这个
整数的范围是在 0 ~ 4G 之间。
 source
source
看起来问这个问题有些多余,不就是一个连续的整数值地址。如果再深入去看 Linux Kernel,你就会感觉到地址这个概念存在的违和感,地址空间的
变更(比如进程切换时)总是伴随着对段寄存器的修改。
段寄存器和逻辑地址
因为我们平时写代码时操作的地址在概念上并不是一个 0 ~ 4G 的线性地址,而是一个逻辑地址而已。
什么叫逻辑地址?
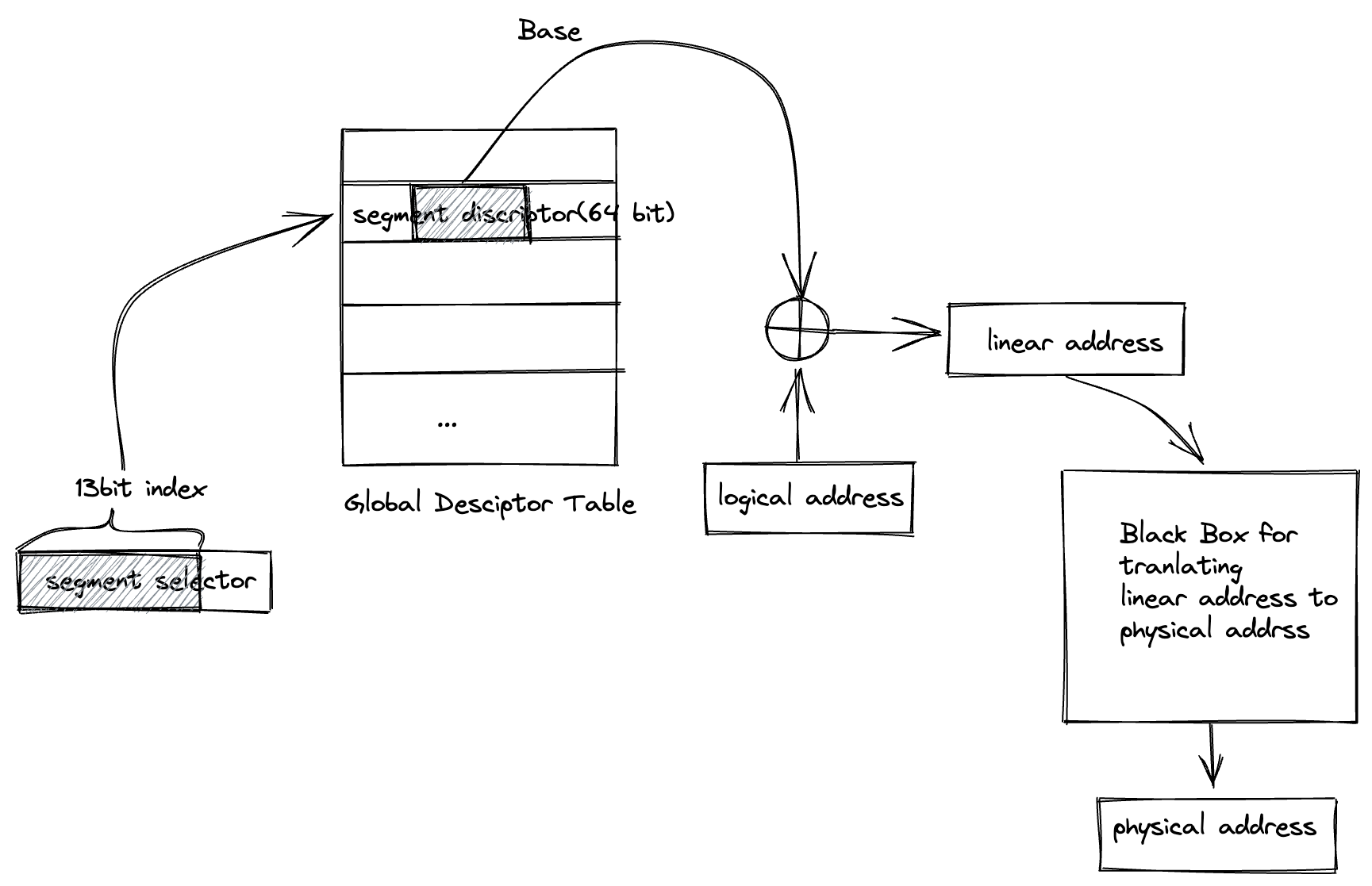
这个是 CPU 硬件寻址逻辑产生的一个虚拟概念,表示的是引用对象在段内的偏移量。CPU 其实是按段寻址的,在执行机器指令的时候,会拿到一个逻辑
地址。此时 CPU 首先会读取 16 位代码段寄存器 CS 或者数据段寄存器 DS 中的段选择符, 将高 13 bit 转成一个整数索引号,然后去全局描述符表中
查询对应的段描述符(全局描述符表是个内核级别的表,专门存放 64 位的段描述符,在内核初始化的时候被初始化, 后面描述内核加载的博客中会提到)。
每个段描述符有 64 bit,其中包括段相对于线性地址 0 的基址偏移。CPU 将这个基址偏移量加上逻辑地址表示的段内偏移量,就能得到线性地址,再
通过某种方式将线性地址映射成物理地址。拿到物理地址之后,就可以通过内存驱动访问具体物理地址的内存数据。这个流程串起来就是:
 source
source
CPU -> 段寄存器 -> 全局描述符 -> 段基址偏移 Base + 逻辑地址(段内偏移) -> 线性地址 -> 物理地址 -> 内存驱动 -> 内存数据
Linux 中的逻辑地址
既然我们平时操作的地址是逻辑地址,为什么我们在使用上感觉地址更像是个线性地址?
比如我将一个文件映射到进程内存空间时,如果是个新段,则打印地址时偏移量应该从 0 开始才对,但是实际上还是一个很大的数字。
Linux Kernel 在实现上没有使用段描述符中的 Base 段偏移的概念,所有段的段描述符 Base 字段都设置成 0,所以逻辑地址就和线性地址相等了。
解释完逻辑地址这个概念之后,我们就知道内核代码中关于操作段寄存器的意义了。比如用户代码需要读取文件时,需要做用户态到内核态的切换,有对应
的指令将内核代码段 __KERNEL_CS 和内核数据段 __KERNEL_DS 的段描述符装载到 cs 和 ds 寄存器中,以便读取对应段的 Base 字段(都是0)。(我们在说用
户态到内核态切换这个对 Linux 工程师熟悉的表述时,其实它隐藏的流程还是很多的,后面我们讲 CPU 资源管理时再详细说明)。因为逻辑地址和线性
地址的值一样,所以后面我们直接用线性地址去描述用户使用的地址。
线性地址是什么
说到这里,我们只说了逻辑地址到线性地址的转换。
那线性地址又是什么?
虽然在表现形式上是个整数区间内的连续数字,那它要表达什么意义?为什么它和我们常说的物理地址在形式上那么相似?
线性地址是进程地址空间抽象得到的一个概念,为了隐藏内核底层是如何管理物理内存的,内核给用户提供了一个有限的连续地址空间的概念,比如在 32 bit 机器
下进程可以访问 0 ~4G 的空间。这种抽象非常精彩,进程仿佛在独占物理内存,用户能使用完整的连续地址,这非常符合线性的思考习惯。在这层进程
地址空间的抽象下面,CPU 总是需要获取到具体某个物理内存地址的数据,加载到寄存器中进行操作,这里就是 Linux Kernel 的分页管理。
分页管理
如何高效得利用内存资源一直是内核关注的问题,比如物理内存大小是256M,当只有一个进程时是不是直接将 256M 的空间 1:1 直接映射到 4G 线性地址空间的
低地址(0~256M)?或者我们有 10 个进程,每个进程有 4G 的线性空间,那要如何映射 256M 的物理内存才能满足用户需求?
我们知道,即使是一个进程,用户指令在运行时也不可能在短时间内访问大范围的内存空间,这就是 locality 原理,所以就会有热内存区间和冷内存区间。
比如 4G 中,只有 100M 是热内存区间,其他的都是冷内存区间,甚至可能大部分进程只会访问总量是 200M 的地址区间(可能是离散的)。在这种情况下,将物理
内存区间固定映射到线性地址空间中,就会有很大的资源浪费。怎么解决这个问题?内存复用。
内存复用的意思是说,我希望同一块物理内存,当进程A 主动释放或者长时间不使用这块物理内存时,就将这块内存给进程 B 使用。为了隐藏底层的内存复用, 我在线性地址和物理地址之间搞个表维护这种映射关系以便可以查找,比如线性地址 [0, 10) => 物理地址 [1000, 1010)。
内存块大小
实际的 Linux 将内存块的大小设置成 4K 或者 2M 或者 4M,称这样大小的连续内存块为页。关于页大小的选择涉及到内存碎片/页内存占用/资源利用率/Copy-on-write 机制效率/内存复用效率等等因素的影响,比如
页大小选择很小(256 Bytes), 此时 32 位地址的低 8 bit 表示块内偏移,剩余的高 24 bit 需要作为页的索引。假设每个页都需要 24 bit
作为页表项实现寻址,如果页表项全部加载到内存中,则需要(24*(2^24))/8=48MB。又比如说如果页大小是 256 Bytes,当内核或者用户
申请释放了大量的单页之后,再申请连续的大内存块,就会申请失败,即使从剩余内存总量上看还是充足的(外部碎片,无法找到连续物理地址内存块)。又比如对于 Copy-on-write 机制,页大小
是 16M 时复制就很慢,也不够灵活。对于此类讨论,可以参考 stackover 上的一个 intel 推荐答案,
或者查看阅读推荐中的参考论文。
 source
source
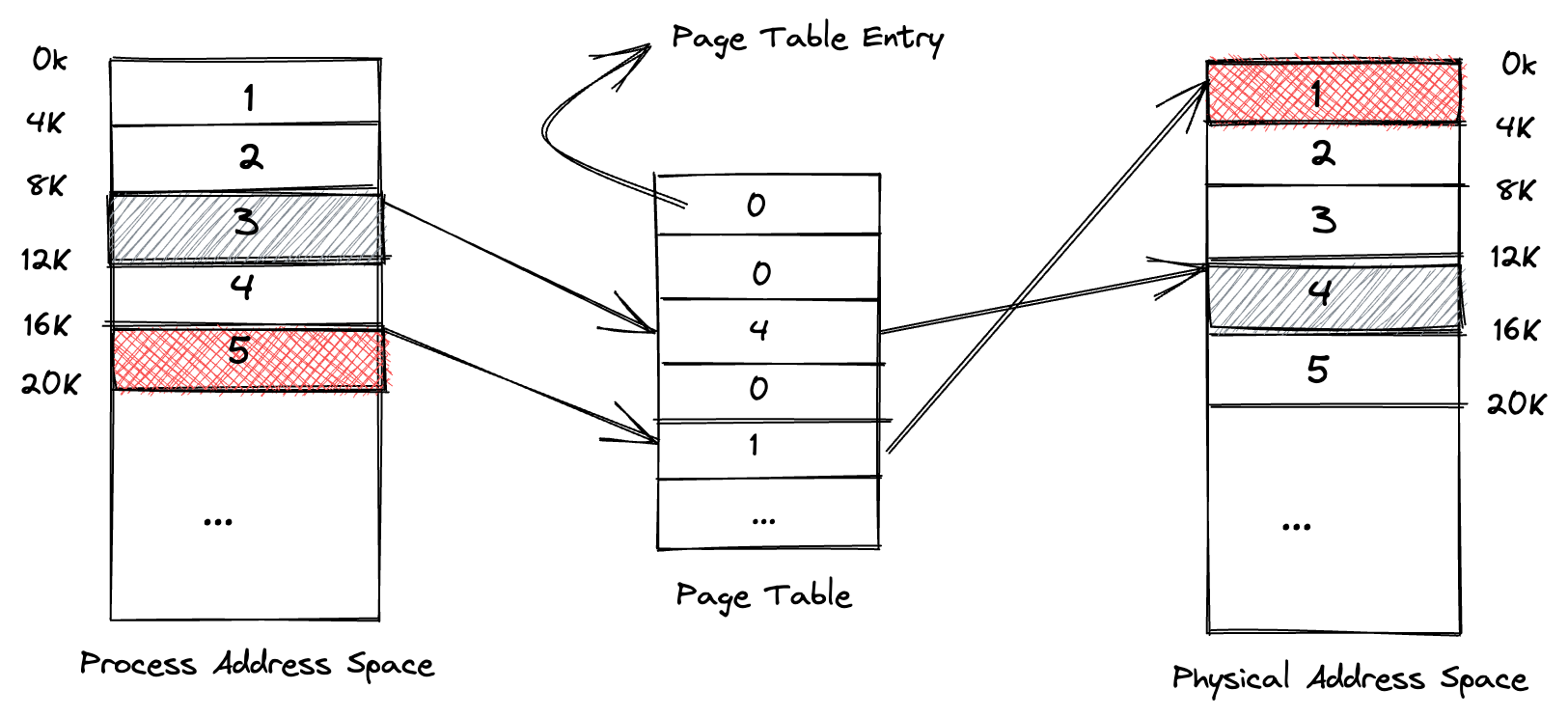
一般情况下,进程线性地址空间划分的页大小和物理地址空间划分的页大小保持一致。此时,对于任何一个线性地址,假设页大小为 4K,将线性地址右移 12 bit 后得到的 就是对应的线性地址空间页索引,我们通过页索引到进程页表中查询对应的物理页索引,就能获取到对应页的物理地址。举个例子:
线性地址:0x00003012
对应的线性地址空间页索引:0x00003 = 3
我们查找进程页表中索引为3的页表项:获得对应的物理页表索引是 4
则对应的物理页地址为:0x00004000
对应的物理地址为:0x0004012
上图中左边的进程地址空间和右边的物理地址空间都只是虚拟概念,即使是分页也只是虚拟概念,这意味着我们在分配地址空间时总是从 4K 对齐的地址开始切分,在实现 上只是一个计算,而中间的页表是实际存在的,存在于内核分配的内存中,其中保存了进程地址空间页索引到物理空间页索引的对应关系。
多级页目录
Linux 默认页大小为 4K,则高 20 bit 需要作为页索引,此时我们可以使用大于 20 bit 的页索引项。假设我们选择 20 bit 的页表项,则为了完成对 整个进程地址空间的寻址,则页表大小为 (20*(2^20))/8 ~= 3MB,注意这里的 3MB 是物理地址占用,也就是每个进程需要大约 3MB 的元数据去完成 4G 地址空间的寻址,完成每个线性地址空间中的页到物理空间页的映射。当操作系统大概有 300 个进程时,所有的进程页表就占用了近 1G 的物理内存, 这明显是不合理的设计。同时,很少有进程会访问到所有线性地址空间,进程在访问线性地址空间时也基本遵循 locality 特性,所以多级页目录 设计就尤为重要。
多级页目录设计思想是,既然进程很少访问大量线性地址空间,那就没有必要一开始就维护所有线性页到物理页映射关系,也就是没有必要维护对应的 页表项,只有在需要的时候再分配内存维护就行。这就有点类似一本 1000 页的书,有个章节目录,目录中有 20 个章节。假如每个章节都是可拆卸的,我们把 书带到咖啡厅去看时,带整本书太重了,同时也不可能在 2 小时内浏览所有的章节,所以我们可以只带其中的 2 个章节,其他章节需要的时候再带。
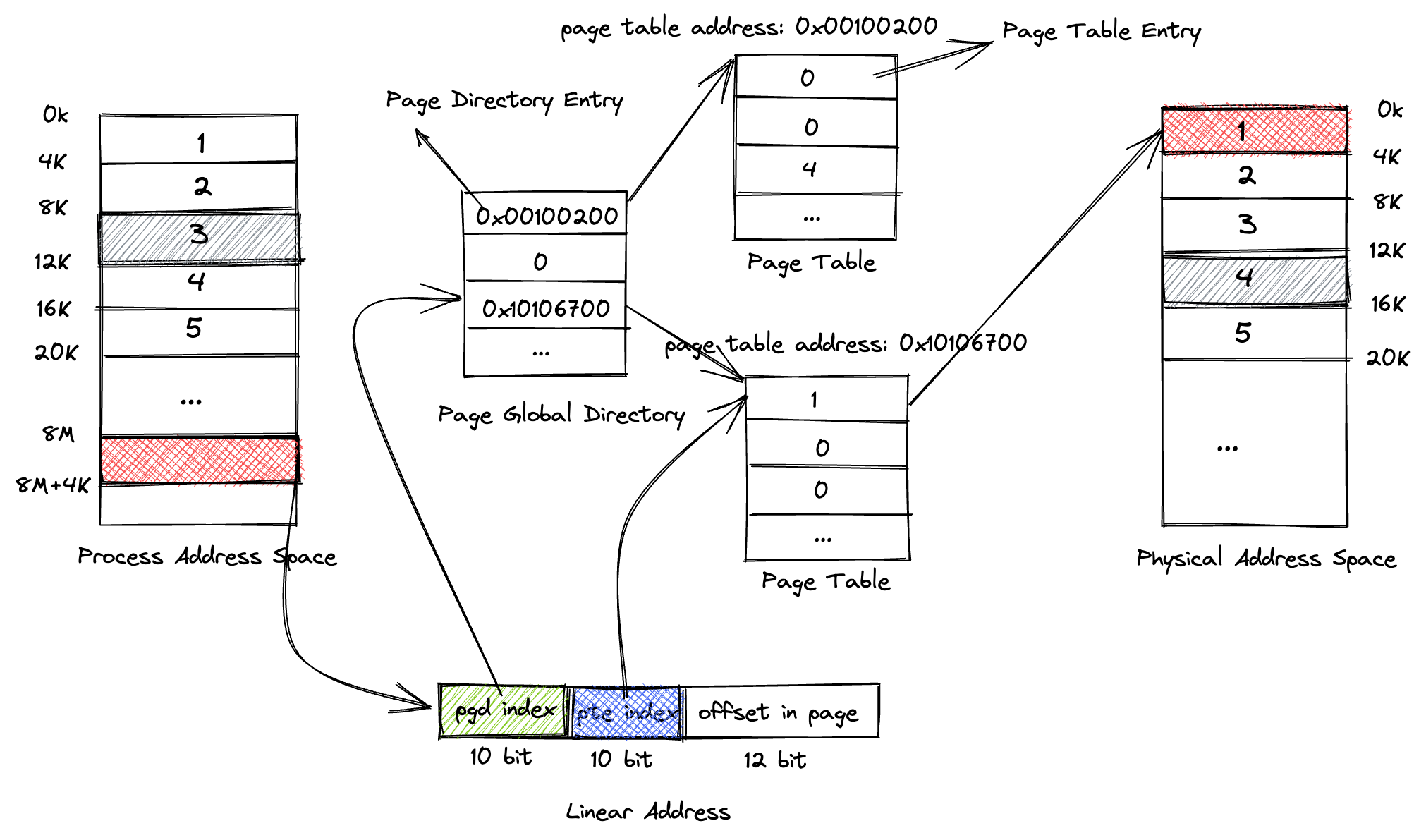
上图中我们可以看到,32 bit 的进程线性地址,高 10 bit 作为页全局目录的索引,中间 10 bit 是页表的索引,低 12 bit 则是 4K 页中的偏移。
- 一个进程在初始化时,只需要页全局目录。由于页全局目录中的每一项都要能够指向一个页表,所以这里我们可以用 32 bit 直接存储页表的地址,也就是说页全局目录中 页目录项都是 4 bytes。总共有 2^10 = 1024 个页目录项,刚好需要 4K 的物理内存占用。
- 当我们真正需要分配物理页时,先通过进程线性地址的高 10 bit 去页全局目录中查询。如果索引对应的页目录项为 0,说明对应的页表还不存在,就要分配页表。由于 每个页表中要存储 2^10 = 1024 个页表项,每个页表项至少需要 32-12 = 20 bit 作为物理页索引,所以当我们使用 4 bytes 的页表项时,每个页表需要 4K 的 物理内存。
- 现在我们分配了对应的 4K 大小的页表,根据中间 10 bit 的值找到对应的页表项。如果页表项为0,就申请一个物理页,并把物理页索引填充到页表项 中。这样我们就完成了整个进程线性地址到物理地址的转换。
从整个多级页目录的设计也可以看出,现在每个进程关于虚拟内存的管理在初始化时只占用了 4K 的空间(页全局目录),页全局目录中的每个页目录项可以管理 2^22 = 4M 的地址空间,每个页表项管理一个页大小 4K 的地址空间。
有了内存分页机制和页表映射,我们就实现了线形地址到物理地址的转换。现在我们就可以想象 CPU 拿到指令中的逻辑地址时,大概经过了哪些流程从而获 取到确定物理地址上的数据。
内核的内存管理是怎样的
到这里就结束了吗?仔细想想感觉漏了一点什么。线性地址空间的抽象让用户进程感觉自己独占了整个 CPU 和内存,上面提到其实背后有分页管理的内存复用。 如果再深入想想,用户在写代码时在一个抽象的线性地址空间里假装自己在利用一段线性的空间,那内核是在哪里起作用的?我们常说进程地址空间中 3G~4G 是内核空间,用户不可以访问,到底它是什么意思?实现上是怎样的?为什么我们不可以直接访问 3G~4G 的空间?
前面我们说过内核是什么,内核在静态概念上只是数据和指令按某种格式组织在一起的文件。进程在运行时内核在哪里?进程使用了内核管理的物理页,那内核 自己的内存用的是什么?指令地址和数据地址是真实的物理地址?内核自己的内存是怎么组织的?鸡生蛋,鸡表示内核,蛋表示进程线性地址空间背后的物理内存页的话,鸡自己也 在物理内存中,那谁生的鸡?如果不能从操作系统加载开始搞清楚整个内存管理和分配的全貌,就还是会对内存分页管理这种偏异步的抽象感到迷惑,脑子里不 能直接想象出整个内核和用户对内存使用的流程。
推荐阅读
如果想要了解更多相关内容,请直接阅读:
- 《Understanding The Linux Kernel》Daniel P.Bovet & Marco Cesati
- 《Modern Operating System》Andrew S.Tanenbaum & Herbert Bos
- 内核源码 https://www.kernel.org/