
Background
Today, let’s discuss a lighter topic about the precision loss of floating-point numbers. This stems from my curiosity about 3 questions:
- The inherent precision loss when representing decimal numbers in binary, such as the decimal 0.1 which corresponds to the binary 0.00(1100)(1100)…
- The limitation of floating-point numbers in representing digits after the decimal point, leading to truncation, for example, 1.123456789 might be represented as 1.123457.
- The third issue is particularly peculiar: although the maximum range of float can reach $2^{127}$, when an integer exceeds $2^{24}$, there is still an integer precision loss issue, causing some programs to use decimal strings to represent large numbers like “100000123”.
Run the following test program on the online compiler:
#include <iostream>
int main() {
//1. binary format precision loss
float small_ft=0.3;
std::cout << "1. original float: 0.3" << std::endl;
std::cout << "1. after assigned to float(rounded):" << small_ft << std::endl;
std::cout << "1. check equity:" << (small_ft==0.3) << std::endl;
//2. significand precision loss
float big_sf=1.123456789;
std::cout << "2. original float: 1.123456789" << std::endl;
std::cout << "2. after assigned to float:" << big_sf << std::endl;
//3. big int precision loss in float
int big_int=100000123;
std::cout << "3. original big int:" << big_int << std::endl;
float ft_int=big_int;
std::cout << "3. after assigned to float:" << ft_int << std::endl;
std::cout << "3. after assigned to float(int):" << (int)ft_int << std::endl;
return 0;
}
Result:
1. original float: 0.3
1. after assigned to float(rounded):0.3
1. check equity:0
2. original float: 1.123456789
2. after assigned to float:1.123457
3. original big int:100000123
3. after assigned to float:1e+08
3. after assigned to float(int):100000120
If 1 and 2 are intuitive, as any representation method will have certain precision limitations, then 3 is somewhat counterintuitive. Large integers do not require precision after the decimal point and do not exceed the maximum positive integer range that float can represent, yet there is still a precision loss, which is quite strange.
float Standard
To explain this issue, let’s quickly walk through the properties provided by the float standard.

For 32-bit float (similarly for double), the highest 1 bit represents the $sign$, the following 8 bits represent the $exponent$ (base 2), and the lowest 23 bits represent the $significand$, which is the precision.
A key point to note here: This is a scientific notation representation. For example (scientific notation in base 10):
$0.000123$ => $1.23 * 10^{-4}$
$22345$ => $2.2345*10^{4}$
According to the float standard, the $exponent$ part’s base is 2, and the $significand$ part represents the significant digits after the decimal point in scientific notation. This is slightly different from our usual concept, where we might think the significand of $123.456$ is “456”, but for float, it is “23456”.
So roughly, $123.456$ is represented as: $1.23456 * 10^{2}$ => $-1^{s} * 1.significand * 2^{exponent}$
where the exponent can be imagined as dividing $123.456$ by 2 repeatedly until the integer part is 1.
=> $-1^{0}* 1.929 * 2^{6}$, $exponent$=6, $significand$=0.929.
The actual float representation is not exactly like this, with some details:
- The $exponent$ has a $-127$ bias, meaning the original 8 bits represent $[0, 255)$, but actually need to calculate $exponent-127$, representing $[-127, 128)$.
- The float standard reserves the $exponent$ values of all 0s and all 1s to represent values too small to represent infinity and values too large to represent $NaN$.
- The actual exponent range is $[-126, 127)$, with $-127 (0-127)$ and $128 (255-127)$ reserved for other meanings.
So the actual float representation is: $-1^{s}* 1.significand * 2^{exponent-127}$.
From this form, the representable range of float is around $[-2^{127}, 2^{127}]$, and the minimum precision it can represent is around $2^{-126}$, with smaller precision values being unrepresentable.
Why Precision Loss Occurs
With the float standard as a foundation, let’s look at the precision loss in scenarios 1, 2, and 3.
Scenario 1: float representing 0.3
This scenario is about the inherent inability of binary to represent certain decimal fractions.
0.3 in decimal scientific notation is $3 * 10^{-1}$, converted to binary scientific notation is: $1.2 * 2^{-2}$
=> $sign$=0, $exponent$=125(-2+127), $significand=b00110011 001100110011010$
where the significand is rounded up to 23 bits from the repeating pattern 0011.
Let’s verify:
#include <iostream>
int main() {
union {
float input;
int output;
}u;
u.input=0.3;
std::cout << "sign:" << (u.output >> 31) << std::endl;
std::cout << "exponent:" << (u.output >> 23) << std::endl;
int tmp= (u.output & 0x7FFFFF);
std::cout << "significand:";
for(int t=22; t>=0; --t) {
std::cout << ((tmp>>t)&0x1);
}
std::cout << std::endl;
}
Result:
sign:0
exponent:125
significand:00110011001100110011010
Scenario 2: float representing 1.123456789
This scenario is about the 23-bit significand determining the maximum precision it can represent, which is around $2^{23}\approx8000000$, so it can represent about 6-7 decimal places.
1.123456789 in binary scientific notation is $1.123456789 * 2^{0}$
=> $sign$=0, $exponent$=127(0+127),
=> $significand=b00110011 001100110011010\approx1.12346$
Let’s verify:
#include <iostream>
int main() {
union {
float input;
int output;
}u;
u.input=0.3;
std::cout << "sign:" << (u.output >> 31) << std::endl;
std::cout << "exponent:" << (u.output >> 23) << std::endl;
int tmp= (u.output & 0x7FFFFF);
std::cout << "significand:";
for(int t=22; t>=0; --t) {
std::cout << ((tmp>>t)&0x1);
}
std::cout << std::endl;
}
Result:
original float: 1.123456789
after assigned to float(rounded):1.12346
sign:0
exponent:127
significand(int):1035631
significand:00011111100110101101111
Scenario 3: float representing 16800013
Scenario 3 is a more counterintuitive scenario. The float standard can represent floating-point numbers in the range of $[-2^{127}, 2^{127}]$, but this does not mean that precision loss will NOT occur within this range.
Consider the decimal scientific notation of 16800013 as $1.6800013 * 10^{7}$, and since the significand in the binary representation of float can only represent 6-7 decimal places, 0.6800013 will be truncated.
Let’s directly switch to binary scientific notation $1.001358807086*2^{24}$, where 0.001358807086 is the truncated decimal fraction. After representing it with 23 bits in binary, it will be further truncated, so the integer represented by float will be the truncated version.
Let’s verify:
#include <iostream>
int main() {
union {
float input;
int output;
}u;
u.input=16800013;
std::cout << "original float: 16800013" << std::endl;
std::cout << "after assigned to float(rounded):" << u.input << std::endl << std::endl;
std::cout << "float to int:" << (int)u.input << std::endl << std::endl;
std::cout << "sign:" << (u.output >> 31) << std::endl;
std::cout << "exponent:" << (u.output >> 23) << std::endl;
int tmp= (u.output & 0x7FFFFF);
std::cout << "significand:";
for(int t=22; t>=0; --t) {
std::cout << ((tmp>>t)&0x1);
}
std::cout << std::endl;
}
original float: 16800123
after assigned to float(rounded):1.68e+07
float to int:16800012
sign:0
exponent:151
significand:00000000010110010000110
From the results, we can see that after assigning 16800013 to float, converting it back to int results in 16800012.
I specifically chose 16800013 because it is slightly larger than $2^{24}$, and 24 bits represent 23 bits significand + 1 bit of leading 1, so integers within the range of $[-2^{24}, 2^{24}]$ can be fully represented.
For numbers larger than $2^{24}$, their binary representation will have more than 24 bits. When the decimal point is moved to the leading 1, the bits after that exceed 23 and will be truncated by the significand.
Decimal: 16800013
Hex: 0x100590D
Binary: 0001 [0000 0000 0101 1001 0000 1101]
float: 1.[0000 0000 0101 1001 0000 110] * 2^(24)
double Standard
The analysis process for double precision is the same as for float. You can refer to the above analysis. The standard is here:
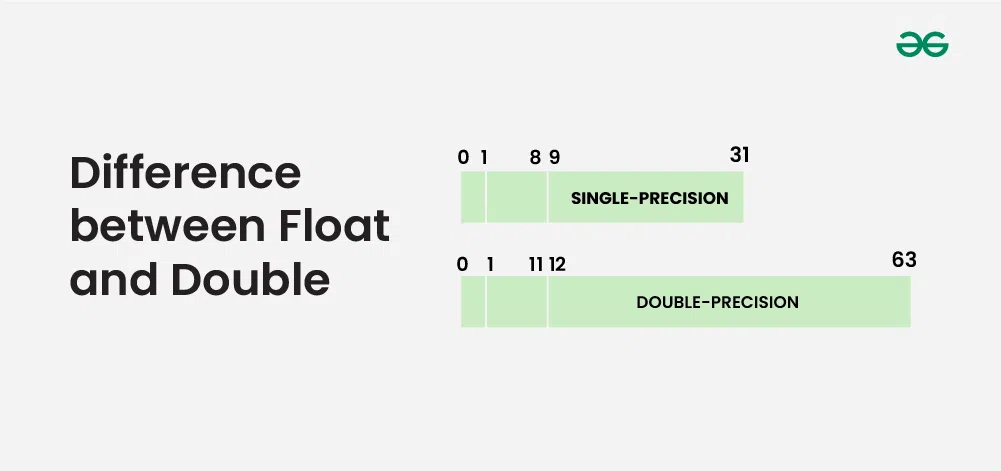
Under the double standard, since the significand can have up to 63 bits, for positive integers, there will be no truncation issues within approximately $10^{18}$. This is also why Lua can use the number type to represent both integers and floating-point numbers (from Programming in Lua).

Conclusion
Float and double are very common built-in types in programming languages, but their encoding method makes their meaning less intuitive than integer and string types.
In most scenarios, we do not encounter or pay attention to the precision loss of float because the rounding up of float itself may mask the issue. However, in fields like billing and scientific computing, where precision is crucial, it is essential to pay special attention to the various scenarios of floating-point precision loss.
This article focuses on explaining the reasons for precision loss in float when representing special decimals, long significant digits, and large integers.